

Le nouvel ensemble LEGO Ideas La machine à écrire est disponible, un petit bijou de 2079 pièces à construire !
]]>JHipster supports back-end code in Spring Boot and front-end code in Angular/React/Vue.js.
]]>Le nouvel ensemble LEGO Ideas La machine à écrire est disponible, un petit bijou de 2079 pièces à construire !
]]>

Grâce à une étude de grande envergure, l'agence spatiale américaine a confirmé l'affaissement de la mésosphère; un phénomène prévisible, en lien direct avec les gaz effet de serre.
]]>Look out, Duke! Don’t run into a cloud!
FXGL, the JavaFX Game Development Framework, is exactly what you need to extend your Java skills to become a game developer. FXGL is a dependency you add to your Java and JavaFX project; it doesn’t need any additional installation or setup. It works out of the box on all platforms.
Thanks to the simple and clean FXGL API, you can build 2D games with minimal code and deliver them as a single executable .jar file or native image. Almas Baimagambetov, senior lecturer in game development at the University of Brighton, is the creator of FXGL, and the project is fully open source and has a clear description about how you can contribute to it.
You can see basic examples of using the FXGL library in the main GitHub project. More-complex games are provided in a separate project, FXGLGames. You can also use FXGL to build business applications with complex UI controls; there are also 3D interface controls in the library, but those are still experimental.
In this article, you will see all the code needed to build a fun game where Duke shoots at a circle while moving around—while avoiding floating cloud servers. Before proceeding, you might want to watch a one-minute video that shows how the game is played.
Oracle Java Magazine—FXGL from Frank Delporte on Vimeo
In a follow-up article, you’ll see how to control the game with a joystick on a Raspberry Pi device. For now, though, the goal is to create the game itself.
Source code and image assetsThe finished project, called JavaMagazineFXGL, is available on GitHub. This is a Maven project you can build with mvn package. In the pom.xml file there is only one dependency, because FXGL itself depends on JavaFX.
<dependencies> <dependency> <groupId>com.github.almasb</groupId> <artifactId>fxgl</artifactId> <version>${fxgl.version}</version> </dependency> </dependencies>The full code for the game consists of only a few classes, which include the EntityFactory, CloudComponent, and PlayerComponent, as well as the Main class and FXGL application overrides.
By default, FXGL loads images from the src > main > resources > assets > textures directory, which has the few images, such as Duke, that are used in the game. (See Figure 1, Figure 2, and Figure 3.)

Figure 1. The Duke character: duke.png

Figure 2. The cloud obstacles: cloud-network.png
![]()
Figure 3. Duke’s bullet: sprite_bullet.png
The EntityFactoryAll the game objects in an FXGL application are of type Entity and need to be defined in an EntityFactory. In this sample game, they are in a class called GameFactory.java.
public enum EntityType { BACKGROUND, CENTER, DUKE, CLOUD, BULLET }By defining an enum with the types, it becomes easier to reference them later, such as in collision detection. For each entity type, a @Spawns annotated method defines the layout and behavior of the object. Both the background and centered circle have a fixed size, which is defined in SpawnData. FXGL offers many components to control the entities, and in this case, the application uses the IrremovableComponent because these entities should never be removed.
@Spawns("background") public Entity spawnBackground(SpawnData data) { return entityBuilder(data) .type(EntityType.BACKGROUND) .view(new Rectangle(data.<Integer>get("width"), data.<Integer>get("height"), Color.YELLOWGREEN)) .with(new IrremovableComponent()) .zIndex(-100) .build(); } @Spawns("center") public Entity spawnCenter(SpawnData data) { return entityBuilder(data) .type(EntityType.CENTER) .collidable() .viewWithBBox(new Circle(data.<Integer>get("x"), data.<Integer>get("y"), data.<Integer>get("radius"), Color.DARKRED)) .with(new IrremovableComponent()) .zIndex(-99) .build(); }For the Duke character and clouds, I gave the images a viewWithBBox for collision detection. I used the FXGL AutoRotationComponent and custom PlayerComponent and CloudComponent because the game needs to add specific controls to these entities.
@Spawns("duke") public Entity newDuke(SpawnData data) { return entityBuilder(data) .type(EntityType.DUKE) .viewWithBBox(texture("duke.png", 50, 50)) .collidable() .with((new AutoRotationComponent()).withSmoothing()) .with(new PlayerComponent()) .build(); } @Spawns("cloud") public Entity newCloud(SpawnData data) { return entityBuilder(data) .type(EntityType.CLOUD) .viewWithBBox(texture("cloud-network.png", 50, 50)) .with((new AutoRotationComponent()).withSmoothing()) .with(new CloudComponent()) .collidable() .build(); }The bullet doesn’t need a custom component, because FXGL’s ProjectileComponent and OffscreenCleanComponent have all the needed functionality.
@Spawns("bullet") public Entity newBullet(SpawnData data) { return entityBuilder(data) .type(EntityType.BULLET) .viewWithBBox(texture("sprite_bullet.png", 22, 11)) .collidable() .with(new ProjectileComponent(data.get("direction"), 350), new OffscreenCleanComponent()) .build(); } The CloudComponentThe CloudComponent class illustrates the flexibility that’s provided by an FXGL component. OnUpdate is called at each engine tick, allowing the game to fully control the behavior of the entity to which the component is attached.
In this case, the game moves the cloud in the direction that was randomly calculated upon initialization of the component. The game checks whether the cloud hits the border of the game and removes it from the game world if it does.
public class CloudComponent extends Component { private final Point2D direction = new Point2D( FXGLMath.random(-1D, 1D), FXGLMath.random(-1D, 1D) ); @Override public void onUpdate(double tpf) { entity.translate(direction.multiply(3)); checkForBounds(); } private void checkForBounds() { if (entity.getX() < 0) { remove(); } if (entity.getX() >= getAppWidth()) { remove(); } if (entity.getY() < 0) { remove(); } if (entity.getY() >= getAppHeight()) { remove(); } } public void remove() { entity.removeFromWorld(); } } The PlayerComponentThe PlayerComponent uses a Point2D object to define Duke’s direction. Initially, Duke moves to the bottom right. The up, down, left, and right methods change the direction gradually defined by the ROTATION_CHANGE value. As with the CloudComponent, there is a check for the borders of the screen, but in this case, the code calls the die method when Duke hits the border.
The die method decreases the “number of lives” value and resets the direction and position to get back to the starting position. When the player doesn’t have any lives left, the game shows a “Game Over” message box.
The shoot method spawns a new bullet at Duke’s current position, giving the bullet the same direction that Duke is traveling in.
public class PlayerComponent extends Component { private static final double ROTATION_CHANGE = 0.01; private Point2D direction = new Point2D(1, 1); @Override public void onUpdate(double tpf) { entity.translate(direction.multiply(1)); checkForBounds(); } private void checkForBounds() { if (entity.getX() < 0) { die(); } if (entity.getX() >= getAppWidth()) { die(); } if (entity.getY() < 0) { die(); } if (entity.getY() >= getAppHeight()) { die(); } } public void shoot() { spawn("bullet", new SpawnData( getEntity().getPosition().getX() + 20, getEntity().getPosition().getY() - 5) .put("direction", direction)); } public void die() { inc("lives", -1); if (geti("lives") <= 0) { getDialogService().showMessageBox("Game Over", () -> getGameController().startNewGame()); return; } entity.setPosition(0, 0); direction = new Point2D(1, 1); right(); } public void up() { if (direction.getY() > -1) { direction = new Point2D(direction.getX(), direction.getY() - ROTATION_CHANGE); } } public void down() { if (direction.getY() < 1) { direction = new Point2D(direction.getX(), direction.getY() + ROTATION_CHANGE); } } public void left() { if (direction.getX() > -1) { direction = new Point2D(direction.getX() - ROTATION_CHANGE, direction.getY()); } } public void right() { if (direction.getX() < 1) { direction = new Point2D(direction.getX() + ROTATION_CHANGE, direction.getY()); } } } Main class and FXGL application overridesWith the three previous classes, everything is prepared to create the game. All that’s left is the main class. The main class combines everything and extends from FXGL GameApplication, which provides multiple override methods to configure your game. These methods are called during initialization in the following order:
Because the game should run full-screen with the right dimensions, the application reads these values in the main method. The game also uses the GameFactory, created earlier, and requires an Entity for the player to contain the Duke entity.
private final GameFactory gameFactory = new GameFactory(); private Entity player; private static int screenWidth; private static int screenHeight; public static void main(String[] args) { Dimension screenSize = Toolkit.getDefaultToolkit().getScreenSize(); screenWidth = (int) screenSize.getWidth(); screenHeight = (int) screenSize.getHeight(); launch(args); }FXGL overrides. GameSettings contains a long list of methods to configure your game. This example uses only those necessary to make the game full-screen and give it a title.
@Override protected void initSettings(GameSettings settings) { settings.setHeight(screenHeight); settings.setWidth(screenWidth); settings.setFullScreenAllowed(true); settings.setFullScreenFromStart(true); settings.setTitle("Oracle Java Magazine - FXGL"); }Override initInput configures the input events that control the game. Because Duke should rotate while the player presses one of the arrow keys, the onKey method is used. Firing a bullet should happen only once each time the space bar is pressed, so this uses the onKeyDown method. onPreInit is not used in this example application.
@Override protected void initInput() { onKey(KeyCode.LEFT, "left", () -> this.player.getComponent(PlayerComponent.class).left()); onKey(KeyCode.RIGHT, "right", () -> this.player.getComponent(PlayerComponent.class).right()); onKey(KeyCode.UP, "up", () -> this.player.getComponent(PlayerComponent.class).up()); onKey(KeyCode.DOWN, "down", () -> this.player.getComponent(PlayerComponent.class).down()); onKeyDown(KeyCode.SPACE, "Bullet", () -> this.player.getComponent(PlayerComponent.class).shoot()); }The game needs a value for the number of lives that are left and a value for the score. Both are defined in initGameVars and used in initUI.
@Override protected void initGameVars(Map<String, Object> vars) { vars.put("score", 0); vars.put("lives", 5); }Let’s add some stuff to the game world! First, add the entity factory that generates the game entities. Then, it’s time to add the spawns: first a full-screen background, then a circle in the middle of the screen and, finally, Duke as the player entity.
@Override protected void initGame() { getGameWorld().addEntityFactory(this.gameFactory); // Background color spawn("background", new SpawnData(0, 0).put("width", getAppWidth()) .put("height", getAppHeight())); // Circle in the middle of the screen int circleRadius = 80; spawn("center", new SpawnData( (getAppWidth() / 2) - (circleRadius / 2), (getAppHeight() / 2) - (circleRadius / 2)) .put("x", (circleRadius / 2)) .put("y", (circleRadius / 2)) .put("radius", circleRadius)); // Add the player this.player = spawn("duke", 0, 0); }Next, define the collision handlers as follows:
Use lambdas to define the type of entities that need to be handled and the actions to be taken.
@Override protected void initPhysics() { onCollisionBegin(EntityType.DUKE, EntityType.CENTER, (duke, center) -> this.player.getComponent(PlayerComponent.class).die()); onCollisionBegin(EntityType.DUKE, EntityType.CLOUD, (enemy, cloud) -> this.player.getComponent(PlayerComponent.class).die()); onCollisionBegin(EntityType.BULLET, EntityType.CLOUD, (bullet, cloud) -> { inc("score", 1); bullet.removeFromWorld(); cloud.removeFromWorld(); }); }The player needs to see the score and lives-remaining variables defined in initGameVars, and this is done with initUI. By binding the textProperty to these values, the onscreen data will always be up to date.
@Override protected void initUI() { Text scoreLabel = getUIFactoryService().newText("Score", Color.BLACK, 22); Text scoreValue = getUIFactoryService().newText("", Color.BLACK, 22); Text livesLabel = getUIFactoryService().newText("Lives", Color.BLACK, 22); Text livesValue = getUIFactoryService().newText("", Color.BLACK, 22); scoreLabel.setTranslateX(20); scoreLabel.setTranslateY(20); scoreValue.setTranslateX(90); scoreValue.setTranslateY(20); livesLabel.setTranslateX(getAppWidth() - 100); livesLabel.setTranslateY(20); livesValue.setTranslateX(getAppWidth() - 30); livesValue.setTranslateY(20); scoreValue.textProperty().bind(getWorldProperties().intProperty("score").asString()); livesValue.textProperty().bind(getWorldProperties().intProperty("lives").asString()); getGameScene().addUINodes(scoreLabel, scoreValue, livesLabel, livesValue); }Those were all the overrides called during the initialization needed for the game. There is one final initialization, but this is called every frame when the game is in play state: The game shall always have 10 clouds on the screen. By adding one cloud per frame, if needed, the clouds will appear one by one at the start of the game.
@Override protected void onUpdate(double tpf) { if (getGameWorld().getEntitiesByType(EntityType.CLOUD).size() < 10) { spawn("cloud", getAppWidth() / 2, getAppHeight() / 2); } } ConclusionThat’s it! That’s all the code you need to have a fully functional game in JavaFX. Thanks to the clever helper methods provided by FXGL, such as FXGLMath.random, you don’t need to write a lot of code or include extra dependencies to achieve very nice results. This example is a nice starting point if you are new to game development. Have fun with the source code, use it as an inspiration, and please share what you created.
A follow-up article will take this game to the Raspberry Pi single-board computer and show how to add physical buttons and a joystick to create a true arcade-like experience.
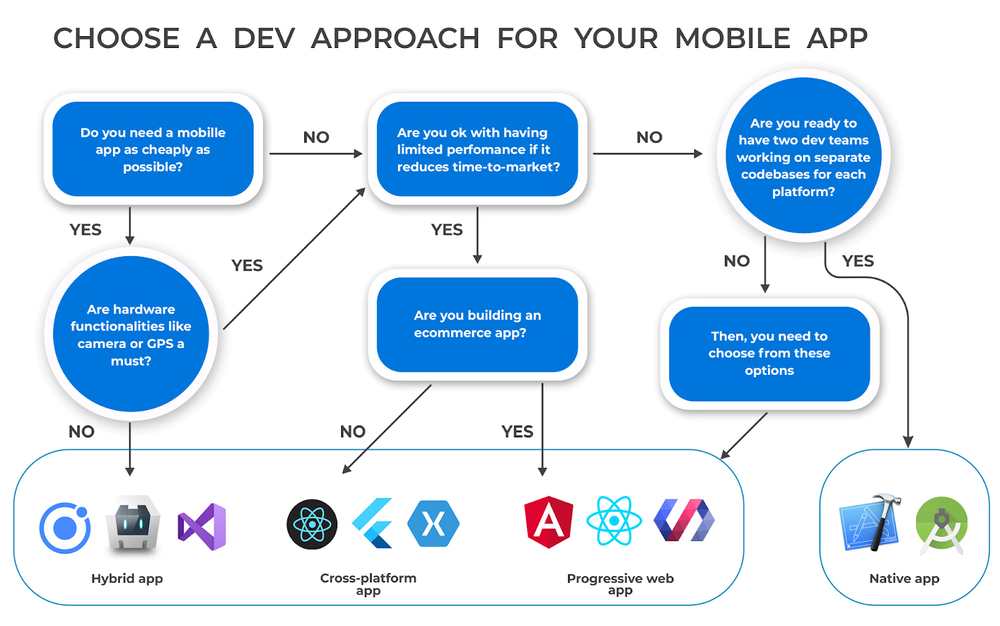
Dig deeper ]]>Il existe actuellement trois types d’applications mobiles : hybrides, multi-plateformes et natives. Dans cet article, je vais les définir car il est important de comprendre la différence entre les trois ainsi que leurs avantages et inconvénients pour choisir celui qui sera le plus adapté à l’application que l’on veut développer. Avant ma conclusion, je ferai un aparté sur les progressive web apps qui sont une sorte d’application mobile un petit peu différente.
Il est difficile de trouver une définition universelle des applications hybrides, notamment en comparaison avec les applications cross-platform. Je vais donc donner ici ma définition.
Les applications hybrides sont des applications codées à partir d’une seule base de code. En revanche, elles sont disponibles pour différents types d’appareils : téléphones Android, téléphones iOS et depuis n’importe quel navigateur internet. Elles utilisent, grâce à des plugins, certaines fonctionnalités natives telles que l’appareil photo, la localisation ou l’accès aux fichiers. Ensuite, le code unique est converti en code natif pour chaque plateforme. Les applications sont rendues grâce à un composant unique appelé Webview, un navigateur internet simplifié intégré à l’application.
Le framework hybride le plus connu est Ionic, même si d’autres sont en usage, comme Apache Cordova qui peut être utilisé pour n’importe quelle application JavaScript.
Les applications multi-plateformes (cross-platform en anglais) ont, comme les applications hybrides, la possibilité de partager le code entre les différentes plateformes sur lesquelles les applications seront déployées.
On retrouve des applications en React Native développé par Facebook sur une base de JavaScript, Xamarin développé par Microsoft et utilise C# ou Flutter développé par Google avec son propre langage Dart. Flutter expérimente une bêta pour fonctionner également sur les navigateurs web.
Par exemple, pour les applications React Native, on peut voir sur le schéma ci-dessous que l’accès aux fonctionnalités natives passe par des ponts JavaScript qui convertissent le code source en code interprétable par l’une ou l’autre des plateformes. Le code JavaScript tourne dans une machine virtuelle qui est capable de communiquer avec les API natives.
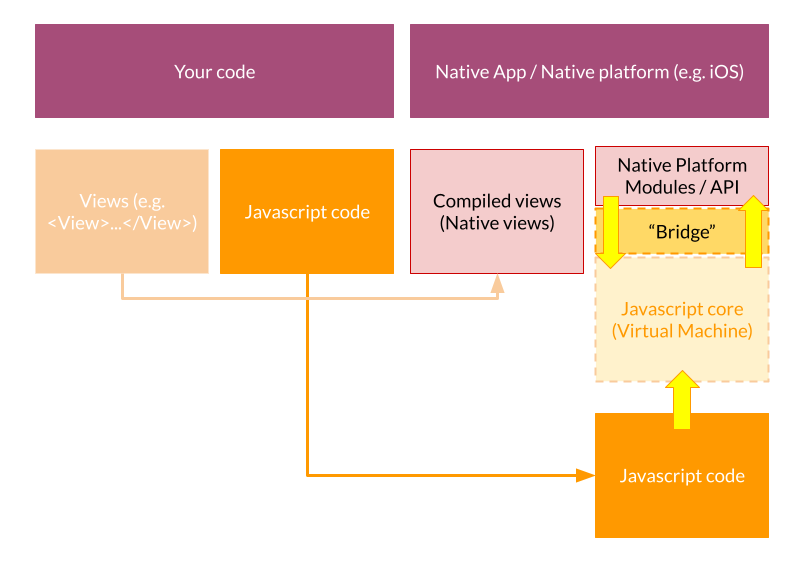
Cette technologie permet en particulier de proposer une expérience utilisateur enrichie car l’application réalisée aura un aspect et un ressenti “natif”. Le code source est unique, mais le code converti utilise les composants natifs pour créer les applications. C’est pour cela que les applications sont disponibles pour Android et iOS uniquement.
Ce sont, comme leur appellation le laisse imaginer, les applications uniquement écrites pour fonctionner sous Android et iOS séparément. Elles sont développées en Java ou Kotlin pour Android et Objective-C ou Swift pour iOS.
Java est un des langages de programmation utilisés pour créer des applications Android. Depuis 2016, Kotlin a amélioré le langage Java en apportant des fonctionnalités et des facilités pour le développeur. L’objectif premier de Kotlin était d’améliorer la qualité du code par rapport au langage Java, en permettant une sécurité contre le nullité des variables, ainsi qu’un kit de développement plus complet.
Voici les principales différences entre Java et Kotlin :
Bien que l’objectif des trois types d’applications citées ci-dessus soit le même, elles diffèrent principalement sur cinq critères :
Native | Hybride | Cross-platform | |
Performance | Très bonne | Mauvaise lorsqu’il y a beaucoup d’animations ou d’images | Moyenne |
Budget | Important car il faut développer pour chaque plateforme | Faible car une seule base de code | |
Time-to-market | Important car il faut développer 2 applications | Très rapide | Rapide |
UI/UX | Conforme aux directives donc correspond à ce qu’attend l’utilisateur | Même rendu sur iOS et Android par défaut, donc peut ne pas tenir compte des directives | Les animations peuvent être moins fluide que sur du natif, mais le reste est proche du natif |
Fonctionnalités | Très proche de l’OS donc faciles d’accès | Certains plugins permettent d’utiliser les fonctionnalités natives, mais cela rajoute de la complexité et est parfois impossible | Les ponts permettent un accès plus facile aux fonctionnalités proches de l’OS, mais il reste parfois quelques fonctionnalités qui sont impossibles à implémenter sans rajouter du code natif (ex : lecteur vidéo) |
Dépendances aux librairies open-source | Faible | Forte | |
Moteur de rendu | Natif | Navigateur (WebView) | Natif |
Courbe d’apprentissage | Peut être assez longue | Rapide si on a déjà fait des applications web | Acceptable |
Un critère essentiel lors du choix du type d’application est la performance. C’est pour quantifier les écarts réels entre les trois types d’applications que des développeurs de la société inVerita ont réalisé un benchmark test [3] entre des applications similaires, développées en React Native, en Flutter et native sur iOS et Android.
Leur conclusion est que les applications natives sont largement plus rapides et moins consommatrices de batterie et de mémoire lors d’opérations gourmandes telles que l’animation ou le chargement de très nombreuses images. Cependant, il est intéressant de noter que Flutter, par exemple, n’est pas si loin derrière. Le choix de la technologie dépendant évidemment du cas d’utilisation, on peut considérer que pour des applications ne nécessitant pas beaucoup de calcul, les applications multi-plateformes satisferont tout à fait les contraintes de performance. Même React Native qui est très consommateur de ressources à cause du pont JS, pourra constituer une base raisonnable. De plus, développer pour deux plateformes entraîne forcément un coût plus conséquent à la création, puis en termes de maintenance. Les développements d’applications hybrides ou cross-platform (React Native, Flutter ou même Ionic) permettent une optimisation sensible, ce qui justifie probablement leur popularité.
Les Progressive Web Apps ne sont pas à proprement parler des applications mobiles, c’est pour cela que je ne les ai pas incluses dans le corps de l’article. Cependant, il me semblait important de les mentionner pour lever le voile sur la confusion.
Les PWA sont des applications web, comme leur nom l’indique, qui vont être optimisées pour mieux fonctionner sur des appareils mobiles. Elles vont également présenter quelques fonctionnalités supplémentaires par rapport à un site web classique [4] :
Elles ne vont cependant pas nécessiter une installation comme une application mobile par exemple. Apple est donc assez opposé au principe des PWA pour deux raisons principales :
On entend parfois parler de générations d’applications mobiles. La première génération serait les applications natives. Ensuite viendraient les applications hybrides. Ce concept a été optimisé pour ne plus être dans une Webview et la 3è génération serait née avec les applications cross-platform. Et enfin, la 4è génération d’applications mobiles serait les PWA. Pourtant, d’une part, les PWA ne sont pas réellement des applications mobiles. Et d’autre part, comme nous l’avons vu au cours de cet article, les “générations” d’applications mobiles ne sont pas mutuellement exclusives. Au contraire, elles présentent des avantages et inconvénients différents, leur permettant d’être adaptées à différents besoins.
[1] Source : Behind the Scenes,React Native - DEV
[2] Source : Native vs. Hybrid vs. Cross-Platform: How and What to Choose?
[3] Source : Flutter vs React Native vs Native: Deep Performance Comparison | by inVerita | The Startup | Jun, 2020
[4] Source : Progressive web application
[5] Source : Native vs. Hybrid vs. Cross-Platform - What Your Product Needs
]]>Le logiciel libre YunoHost vous permet de gérer aisément un serveur web pour vos besoins personnels, professionnels ou associatifs. La version 4.2 vient de sortir début mai. Mode d'emploi.

YunoHost est un système d'exploitation basé sur Debian. Il permet de faciliter l'administration d'un serveur et démocratiser l'auto-hébergement. C'est un projet de logiciel libre maintenu par des contributeurs bénévoles.
La sortie de la version 4.2 de YunoHost s'accompagne de plusieurs nouveautés :
 Réécriture de la webadmin en Vue.js, un framework web plus moderne ;
Passage à Python 3 comme langage de programmation interne, ce qui prépare aussi le terrain pour la transition vers la version Bullseye de Debian, attendue cet été ;
Correctifs pour les domaines nohost.me / noho.st et ynh.fr ;
Permissions pour SSH et SFTP ;
Améliorations au niveau des backups du système.
Réécriture de la webadmin en Vue.js, un framework web plus moderne ;
Passage à Python 3 comme langage de programmation interne, ce qui prépare aussi le terrain pour la transition vers la version Bullseye de Debian, attendue cet été ;
Correctifs pour les domaines nohost.me / noho.st et ynh.fr ;
Permissions pour SSH et SFTP ;
Améliorations au niveau des backups du système.
Vous pouvez télécharger YunoHost depuis cette page, en fonction du matériel dont vous disposez : VirtualBox, Raspberry Pi, carte ARM, ordinateur standard personnel ou ordinateur distant ("Cloud").
Ensuite, vous pouvez installer les applications dont vous avez besoin, depuis un catalogue varié, allant d'AgenDAV à Drupal en passant par NextCloud, Plume, Noalyss, Collabora, Piwigo, etc.
La documentation peut vous aider à choisir le mode d'hébergement le mieux adapté à vos besoins (à la maison, au bureau, via un VPS).
Vous pouvez mettre à jour YunoHost de deux manières :
Depuis la webadmin, via le menu “Mettre à jour le système” ;
En ligne de commande avec les 2 instructions suivantes
$ sudo yunohost tools update $ sudo yunohost tools upgrade —system
Vous pouvez tester YunoHost depuis l'interface utilisateur, en utilisant les identifiant/mot de passe "demo". Une démo est également possible de l'interface d'administration (même mot de passe).
]]> Retrouvez les meilleurs cours et tutoriels pour apprendre Java]]>
Retrouvez les meilleurs cours et tutoriels pour apprendre Java]]>C’est un outil qui va vous éviter de devoir suivre les bonnes pratiques de sécurité à chaque fois que vous avez besoin d’un serveur web ou d’un reverse proxy en frontal de vos services web. Bunkerized-nginx se présente sous la forme d’une image Docker et va s’occuper des paramètres et configurations pour vous. Le but final est d’atteindre une sécurité « par défaut » sans (trop) d’action de votre part.
![]()
Liste non exhaustive des fonctionnalités :
L’outil permet de duper facilement les outils automatisés comme vous pouvez le voir ici.
Il y a une démo en ligne ici : demo bunkerized-nginx. N’hésitez pas à faire des tests de sécurité dessus.
docker network create mynet
docker run --network mynet \
-p 80:8080 \
-v /path/to/web/files:/www:ro \
-e REMOTE_PHP=myphp \
-e REMOTE_PHP_PATH=/app \
bunkerity/bunkerized-nginx
docker run --network mynet \
--name myphp \
-v /path/to/web/files:/app \
php:fpmLes fichiers web sont stockés dans le dossier /www à l’intérieur du conteneur. Veuillez noter que bunkerized-nginx ne tourne pas en root (pour des raisons évidentes de sécurité) mais avec un utilisateur non privilégié ayant comme UID 101 et comme GID 101. Il faut donc mettre les droits sur /path/to/web/files en conséquence.
La variable d’environnement REMOTE_PHP permet de définir l’adresse d’une instance PHP-FPM qui va exécuter les fichiers PHP. Tandis que la variable REMOTE_PHP_PATH permet de définir le chemin utilisé par l’instance PHP-FPM pour chercher les fichiers.
docker run -p 80:8080 \
-p 443:8443 \
-v /path/to/web/files:/www:ro \
-v /where/to/save/certificates:/etc/letsencrypt \
-e SERVER_NAME=www.yourdomain.com \
-e AUTO_LETS_ENCRYPT=yes \
-e REDIRECT_HTTP_TO_HTTPS=yes \
bunkerity/bunkerized-nginxLes certificats sont stockés dans le répertoire /etc/letsencrypt à l’intérieur du conteneur. Il est conseillé de les stocker en local pour pouvoir les réutiliser en cas de redémarrage du conteneur. Veuillez noter que bunkerized-nginx ne tourne pas en root (pour des raisons évidentes de sécurité) mais avec un utilisateur non privilégié ayant comme UID 101 et comme GID 101. Il faut donc mettre les droits sur /where/to/save/certificates en conséquence.
Si vous ne voulez pas que bunkerized-nginx écoute en HTTP, vous pouvez rajouter la variable d’environnement LISTEN_HTTP=no (seulement du HTTPS par exemple). Par contre, Let's Encrypt a besoin du port 80 pour résoudre les challenges, il faut donc garder la redirection.
Ici nous avons 3 variables d’environnement :
- SERVER_NAME : il s’agit du FQDN de votre service (qui doit pointer vers l’adresse IP de votre serveur pour que Let's Encrypt fonctionne)
- AUTO_LETS_ENCRYPT : active la création et le renouvellement automatique de certificats via Let's Encrypt
- REDIRECT_HTTP_TO_HTTPS : active la redirection HTTP vers HTTPS
docker run -p 80:8080 \
-e USE_REVERSE_PROXY=yes \
-e REVERSE_PROXY_URL=/ \
-e REVERSE_PROXY_HOST=http://myserver:8080 \
bunkerity/bunkerized-nginxIl s’agit d’un cas assez simple où il n’y a qu’une seule application derrière le reverse proxy. Si vous en avez plus d’une, vous pouvez utiliser plusieurs fois les variables d’environnement REVERSE_PROXY_URL/REVERSE_PROXY_HOST en rajoutant un nombre à la fin comme ceci :
docker run -p 80:8080 \
-e USE_REVERSE_PROXY=yes \
-e REVERSE_PROXY_URL_1=/app1/ \
-e REVERSE_PROXY_HOST_1=http://myapp1:3000/ \
-e REVERSE_PROXY_URL_2=/app2/ \
-e REVERSE_PROXY_HOST_2=http://myapp2:3000/ \
bunkerity/bunkerized-nginxPar défaut, bunkerized-nginx va seulement créer une seule configuration « serveur » (un seul bloc « server » sera créé dans la configuration nginx). En mettant la variable d’environnement MULTISITE avec la valeur yes, une configuration « serveur » sera créée pour chaque hôte présent dans la variable d’environnement SERVER_NAME. De plus, vous pouvez définir des configurations différentes pour chaque service en préfixant les variables par le FQDN comme ceci :
docker run -p 80:8080 \
-p 443:8443 \
-v /where/to/save/certificates:/etc/letsencrypt \
-e SERVER_NAME=app1.domain.com app2.domain.com \
-e MULTISITE=yes \
-e AUTO_LETS_ENCRYPT=yes \
-e REDIRECT_HTTP_TO_HTTPS=yes \
-e USE_REVERSE_PROXY=yes \
-e app1.domain.com_REVERSE_PROXY_URL=/ \
-e app1.domain.com_REVERSE_PROXY_HOST=http://myapp1:8000 \
-e app2.domain.com_REVERSE_PROXY_URL=/ \
-e app2.domain.com_REVERSE_PROXY_HOST=http://myapp2:8000 \
bunkerity/bunkerized-nginxUSE_REVERSE_PROXY est donc appliquée « globalement » pour chaque serveur. Par contre les variables d’environnement app1.domain.com_* et app2.domain.com_* sont seulement appliquées pour app1.domain.com et app2.domain.com respectivement.
Quand bunkerized-nginx doit lire des fichiers et que MULTISITE a pour valeur yes, le répertoire /www contiendra un sous-dossier par service et chaque sous-dossier aura pour nom le FQDN correspondant dans la variable SERVER_NAME. Prenons cet exemple :
docker run -p 80:8080 \
-p 443:8443 \
-v /where/to/save/certificates:/etc/letsencrypt \
-v /where/are/web/files:/www:ro \
-e SERVER_NAME=app1.domain.com app2.domain.com \
-e MULTISITE=yes \
-e AUTO_LETS_ENCRYPT=yes \
-e REDIRECT_HTTP_TO_HTTPS=yes \
-e app1.domain.com_REMOTE_PHP=php1 \
-e app1.domain.com_REMOTE_PHP_PATH=/app \
-e app2.domain.com_REMOTE_PHP=php2 \
-e app2.domain.com_REMOTE_PHP_PATH=/app \
bunkerity/bunkerized-nginxDans ce cas, le répertoire /where/are/web/files devra avoir une structure comme celle-ci :
/where/are/web/files
├── app1.domain.com
│ └── index.php
│ └── ...
└── app2.domain.com
└── index.php
└── ...Bunkerized-nginx permet de faire bien plus que ce soit la configuration automatique avec des labels, l’intégration dans un environnement Docker Swarm ou même l’utilisation d’une interface web pour configurer les services. Tout est expliqué dans le README du projet GitHub.
Veuillez noter qu’énormément d’éléments de sécurité sont activés avec des valeurs par défaut. Mais vous pouvez tout configurer comme bon vous semble. Pour plus d’informations vous pouvez consulter la liste des variables d’environnement.
Il y a aussi des exemples concrets accompagnés de fichiers docker-compose.yml prêts à l’emploi dans le dossier examples sur GitHub.
Commentaires : voir le flux Atom ouvrir dans le navigateur
]]>Indeed, the use of containers has made the use and adoption of cloud computing a lot easier, and with its most significant differential, the application isolation refuse. Making an analogy with the Java world of which we have the WORA Write Once Read Anywhere with containers, we have the PORA Package Once Run Anytime. Since the container, on a general basis, focuses on being an isolated package within an application. The purpose of this article is not to talk about the inner workings of a container. However, we have this excellent article from Larry that manages to address more about the subject.
]]>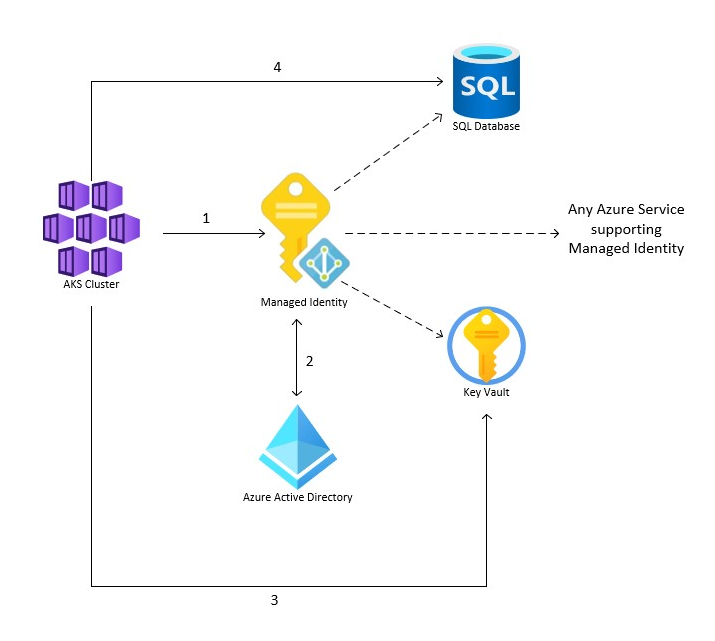
In the first article, we created a very simple Spring Boot App, dockerized it and deployed that to an Azure AD managed AKS cluster using…
]]>WebRTC, pour Web Real-Time Communication, c'est-à-dire communication en temps réel pour le Web, est une interface de programmation (API) JavaScript développée au sein du W3C et de l'IETF. Les groupes de travail W3C/IETF ont débuté en 2011. 10 ans après, WebRTC devient un standard officiel.
WebRTC est un cadre ouvert pour le Web qui permet des communications en temps réel dans le navigateur, à condition bien sûr que celui-ci implémente l'API. WebRTC comprend les éléments fondamentaux pour des communications de haute qualité sur le Web, tels que les composants réseau, audio et vidéo utilisés dans les applications de chat vocal et vidéo.
L'API repose sur une architecture triangulaire puis pair à pair dans laquelle un serveur central est utilisé pour mettre en relation deux pairs (deux navigateurs) désirant échanger des flux de médias ou de données ensuite sans autre relais. Les deux navigateurs téléchargent depuis un serveur une application JavaScript vers leur contexte local. Le serveur est utilisé comme point de rendez-vous afin de coordonner les échanges entre navigateurs jusqu'à ce que la connexion directe entre navigateurs soit établie. A ce moment les deux navigateurs communiquent directement, en étant affranchis du serveur Web.
A l'occasion de cette officialisation de WebRTC, le Dr Jeff Jaffe, PDG du W3C a déclaré "La réalisation historique d'aujourd'hui est opportune. Face à une pandémie mondiale du coronavirus COVID-19, le monde est devenu de plus en plus virtuel. Cela rend le Web encore plus crucial pour la société en matière de partage d'informations, de communications en temps réel et de divertissement. Il est gratifiant de voir nos technologies jouer un rôle clé dans la mise en place d'une telle infrastructure numérique critique. La combinaison de la portée universelle du Web et de la richesse des conversations audio et vidéo en direct a remodelé la façon dont le monde communique. "
Les spécifications de WebRTC sont ici.

Not all releases are created equal and, depending on how feature development phases align; some will have more features than others. JDK 16 contains quite a few new things, although several of them are continuations or finalization of incubator modules or preview features from earlier releases. I think this is one of the biggest benefits of the faster release cadence. Providing new functionality without making it part of the standard, gathering feedback from developers, and potentially making changes has delivered an improved process for the JDK development.
]]>A couple of weeks ago, I gave my talk on Zero Downtime on Kubernetes. A demo is included in the talk, as with most of my presentations. While rehearsing in the morning, the demo worked, albeit slowly. Two days before that, I had another demo that also uses Kubernetes and it was already slow. But I didn't take the hint.
]]>
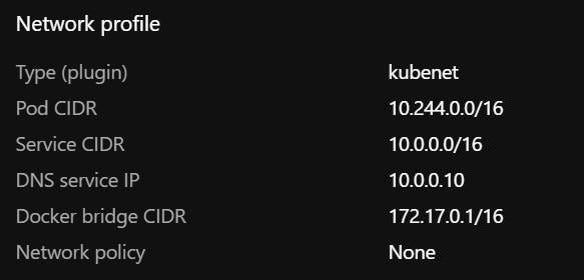
La CNCF propose trois certifications Kubernetes :
CKAD : Certification développeur en environnement micro-service
CKA : Certification dédiée aux administrateurs d’environnements micro-service
CKS : Certification orienté sécurité dans les environnements micro-service
A savoir que Kubernetes est un orchestrateur de container et se veut Cloud Agnostic, Kubernetes peut donc être mis en place chez n’importe quel provider Cloud.
L’examen CKA a changé en septembre 2020, voici les nouvelles grilles de notation des différentes sections :
Voici le contenu des différentes sections :
Cluster Architecture, Installation & Configuration – 25%
Workloads & Scheduling – 15%
Services & Networking – 20%
Storage – 10%
Troubleshooting – 30%
L’examen dure maintenant 2 heures au lieu de 3 heures et comporte 17 questions au lieu de 24 questions. Le score pour l’obtenir est de 66%

La partie Security a disparu, car elle a maintenant sa propre certification CKS. La certification CKA est un prérequis indispensable pour passer la CKS.
Les informations officielles concernant les certifications Kubernetes sont disponibles ici :
Certified Kubernetes Administrator (CKA) | Cloud Native Computing Foundation (cncf.io)
Vous pourrez voir à quoi ressemble l’interface de l’examen :
https://docs.linuxfoundation.org/tc-docs/certification/lf-candidate-handbook/exam-user-interface
Le code suivant permet de bénéficier de 15% sur le prix de l’examen. Vu qu’il est à 300€, c’est toujours bon à prendre : KUBERNETES15
Voici les cours que je vous conseille pour préparer cette certification :
Voici les labs disponibles en ligne :
Il existe des livres vraiment intéressants disponibles sur votre Kindle ou au format papier


Ensuite, je vous invite à tenter la CKS, pour cela, il existe deux supports indispensables pour la préparer.
Tout d’abord les cours suivants disponibles chez UDEMY
Kubernetes CKS 2021 Complete Course + Simulator | Udemy
Certified Kubernetes Security Specialist (CKS) | Udemy
Voici le cours en Francais disponible sur la plateforme EazyTraining
Kubernetes: Devenez Certified Kubernetes Security Specialist - eazyTraining
Puis les livres suivants


Maintenant, c’est à vous de jouer 😉

Avec maintenant presque une décennie de recul, et un engouement réel depuis quelques années, les microservices constituent un style d’architecture couramment adopté... avec plus ou moins de bonheur. Le temps est donc venu de faire le point sur ses avantages et ses contre-indications, ainsi que de dresser la liste des étapes qui permettent de réussir avec ce concept.
Au-delà de la programmation, le développement informatique moderne a pour objet l’intégration de solutions existantes, et la réutilisation d’algorithmes éprouvés en particulier. C’est pourquoi les architectures logicielles vont vers toujours plus de modularité, de découplage. Dans cette optique, l’approche dite “micro-services” opère une sorte de fusion entre les architectures orientées services (ou SOA, faiblement couplées) et les périmètres bornés, ou bounded (business) context. Un concept repris du domain-driven design qui implique par exemple que chaque fonctionnalité soit dotée de son propre schéma de données et de sa propre chaîne dans l'usine logicielle, et où les données fournies restent limitées au strict nécessaire. Quoi qu'il en soit, rappelez-vous que ce ne sont pas les microservices qui délimitent vos fonctions, c'est plutôt votre conception fonctionnelle qui va aboutir à la création de services modulaires, en tenant compte de la fréquence et du volume des échanges entre eux. En appliquant un principe de responsabilité unique (ou SRP), on s’autorise à utiliser pour chaque cas d’utilisation la technologie adéquate (du fait d’échanges via des protocoles agnostiques, par exemple en se basant sur une architecture hexagonale avec des "sas" d'entrée-sortie), et on bénéficie également d’une meilleure évolutivité en ayant le moins d’effets de bord possible. En tout cas, c'est le but recherché, bien qu'il ne soit pas toujours évident de procéder à cette dichotomie avec suffisamment de clairvoyance.
En analysant différents cas, nous avons souvent abordé la question de savoir si ce type d’architecture devait être généralisé dans les solutions développées, notamment dans le cadre de la migration des produits vers un déploiement Kubernetes (c’est-à-dire la virtualisation orchestrée, via des conteneurs). Mais il n’y a pas de réponse évidente :
La décision d’appliquer ou non une architecture microservices s’avère donc plus délicate en pratique, que ne semble l’indiquer l’engouement affiché pour elle, avec une profusion d’articles et de cadriciels dédiés, dans les langages les plus populaires. Est-ce que toutes les applications doivent systématiquement être converties ? Nous ne le pensons pas. Est-ce qu’avec leur conversion les applications verront tous leurs problèmes résolus pour autant ? Nous ne le pensons pas non plus. Voici donc quelques critères permettant de s’organiser :
Comme on le voit, toutes les applications ne justifient pas l’emploi des "grands moyens", tandis que pas mal de solutions intermédiaires permettent d'orienter leur évolution selon un rythme soutenable, tout en continuant à gérer des services plus monolithiques. Nos équipent accompagnent tous les jours des projets se trouvant à des stades différents de cette migration. Notre recommandation est de n’envisager la modularisation fine des services que dans la mesure où ce découpage doit avoir un impact sur les performances ou l’évolutivité des produits. Vous disposerez ainsi d’une granularité d'analyse vous permettant de savoir quelles nouvelles refontes architecturales seront vraiment nécessaires. La meilleure pratique étant d'établir, préalablement à la migration architecturale, une cartographie des projets existants et des besoins, puis une évaluation précise des enjeux.
Pour aller plus loin et maîtriser les subtilités qui se cachent derrière la décomposition des applications monolithiques en micro-services, nous vous recommandons les conférences de Sam Newman et la lecture de son livre : Monolith to Microservices - Evolutionary Patterns to Transform Your Monolith.
Voici selon lui les trois principales justifications d'une telle migration, qui doit toujours se faire progressivement (strangler fig pattern) :
Technosaures #5 vient de paraître ! Dans ce numéro de Technosaures, nous vous parlons du Commodore SX-64, de l’Amiga 2000, de l’Atari ST, de l’Apple IIGS, des accessoires pour améliorer son ancienne machine et d’un superbe nouveau jeu disponible sur Atari ST, Athanor 2.
+ une petite histoire du DynaBook. Avec 40 ans d’avance, Alan Kay invente la tablette !
Technosaures #5 est disponible dans notre boutique en ligne.


This is the fourth and final post in the ongoing series on understanding Kubernetes Networking.
In this post, we will discuss on External to Service communication.
If you have missed Part 3 on pod to service communication, you can check it here.
Example:


KUBE-SERVICES is the entry point for service packets. What it does is to match the destination IP:port and dispatch the packet to the corresponding KUBE-SVC-* chain.
KUBE-SVC-* chain acts as a load balancer and distributes the packet to KUBE-SEP-* chain equally. Every KUBE-SVC-* has the same number of KUBE-SEP-* chains as the number of endpoints behind it.
KUBE-SEP-* chain represents a Service Endpoint. It simply does DNAT, replacing service IP:port with Pod’s endpoint IP:Port.
[ Above excerpt is directly from: https://kubernetes.io/blog/2019/03/29/kube-proxy-subtleties-debugging-an-intermittent-connection-reset/#pod-to-service ]
Now, let’s try to expose a service via Ingress-Controller.
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: hello-kubernetes-ingress
annotations:
kubernetes.io/ingress.class: nginx
spec:
rules:
- host: first.com
http:
paths:
- backend:
serviceName: hello-first ## This is the first app.
servicePort: 80
- host: sec.com
http:
paths:
- backend:
serviceName: hello-second ## This is the second app.
servicePort: 80




This brings to the end of the post and the series.
Hope you all liked it.
Understanding Kubernetes Networking — Part 4 was originally published in Microsoft Azure on Medium, where people are continuing the conversation by highlighting and responding to this story.
]]>This is the third post in the ongoing series on understanding Kubernetes Networking.
In this post, we will discuss on POD to Service communication.
If you have missed Part 2 on pod to pod communication, you can check it here.
1.) Manages state of PODs,
2.) Keeps track of PODs IP addresses,
3.) Provides Internal and External L3/L4 connectivity,
4.) Exposes specific VIP (which does not change) behind which PODs are kept.
More Information: https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/
- either via “userspace” proxy mode. [We will not discuss this, as it old and slow and not recommended]
- or via “Iptables” proxy mode.
- or via “IPVS” proxy mode.
rr: round-robin
lc: least connection (smallest number of open connections)
dh: destination hashing
sh: source hashing
sed: shortest expected delay
nq: never queue
More information: https://kubernetes.io/docs/tasks/administer-cluster/dns-custom-nameservers/
[ You can think of it like a normal LB scenario in Azure, accessing IIS page behind LB. Client will only see the LB IP communicating and the backend server will see the Client IP communicating. ]
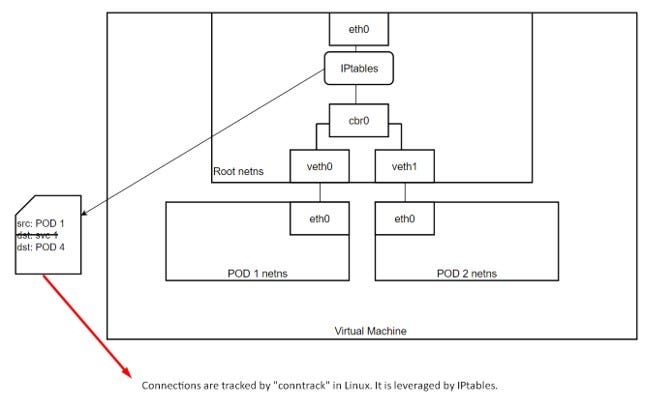


and that concludes this post.
See you on the next one!!!
Understanding Kubernetes Networking — Part 3 was originally published in Microsoft Azure on Medium, where people are continuing the conversation by highlighting and responding to this story.
]]>This is the second post in the ongoing series on understanding Kubernetes Networking.
In this post, we will discuss on POD to POD communication.
If you have missed Part 1 on container to container communication, you can check it here.
- Intra-Node communication of PODs.
- Inter-Node communication of PODs.
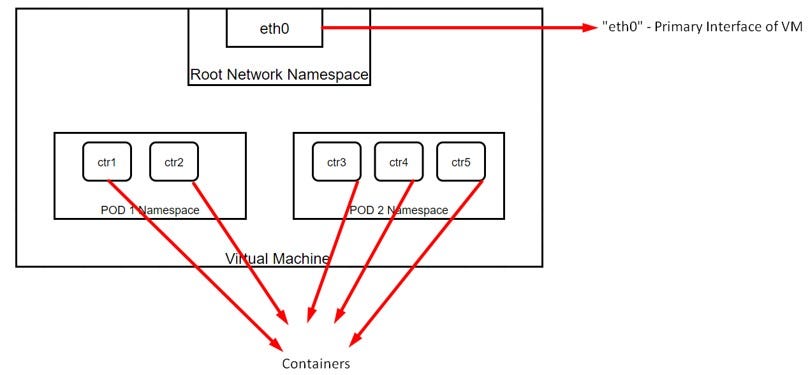
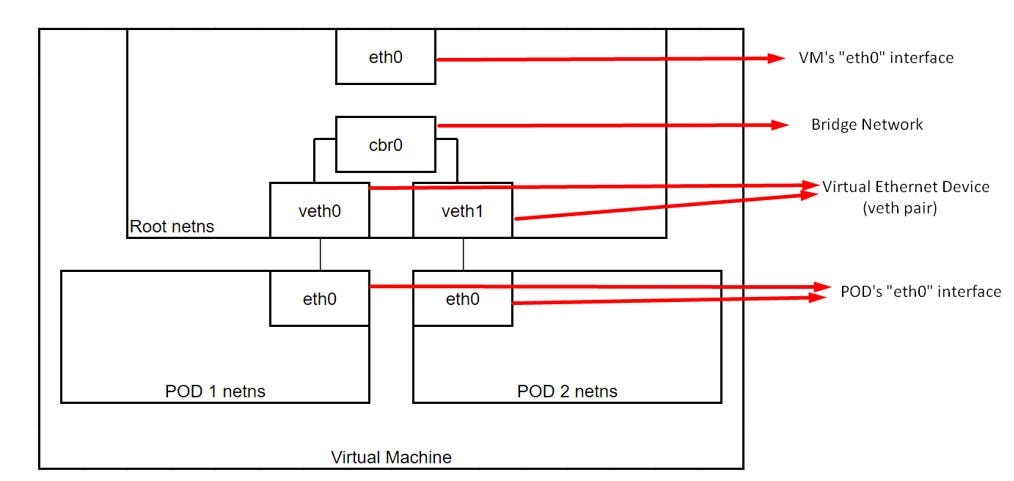
Now, if a packet needs to go from POD 1 to POD 2:
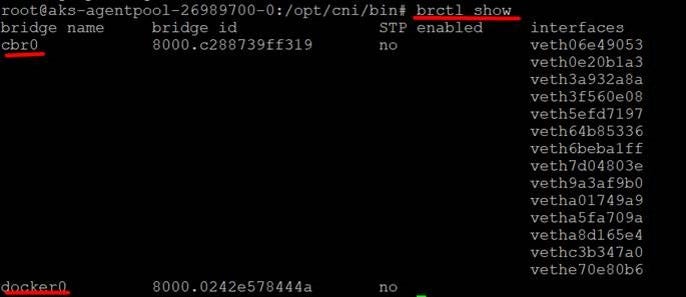

- “Flannel” — used for creating overlay network.
- “Calico” — uses BGP protocol for routing.
More Information:
- https://github.com/containernetworking/cni/blob/master/SPEC.md#cni-plugin
- https://www.youtube.com/watch?v=l2BS_kuQxBA
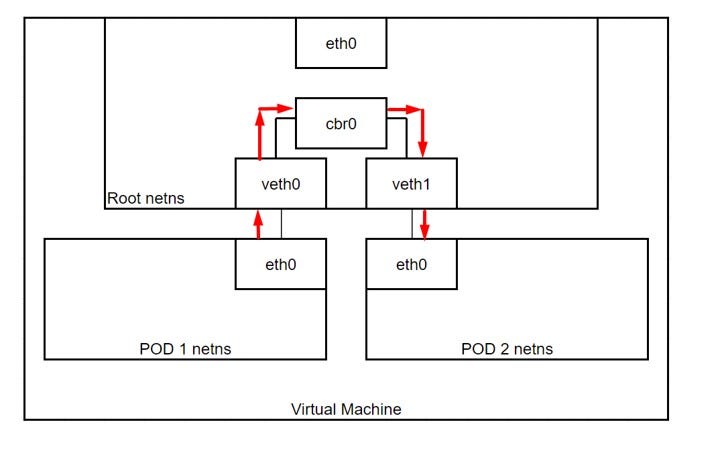
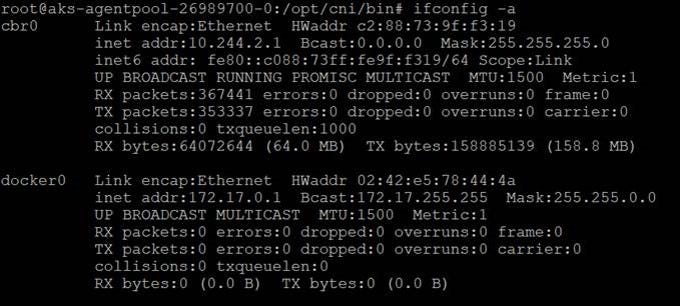
In my current configuration the IP addresses are:
Nodes are deployed in a subnet: 10.240.0.0/16 .
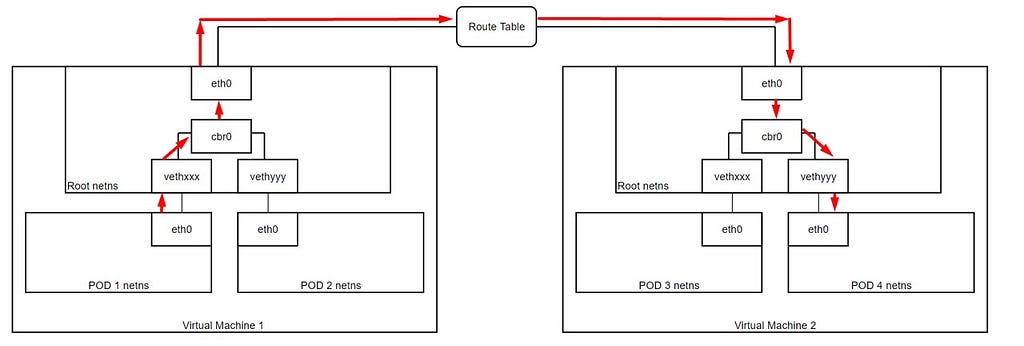


If we assume that the src is: 10.244.1.6 (POD 1) and dest is: 10.244.2.6 (POD 4).
Using UDR packet from 10.244.1.6 is correctly routed to right node with dest as: 10.244.2.6.
Once the packet is inside the other node, it does a route lookup and send packet to “cbr0”.
This brings us to the end of this post.
In the next post, we will discuss about POD to Service communication.
Understanding Kubernetes Networking — Part 2 was originally published in Microsoft Azure on Medium, where people are continuing the conversation by highlighting and responding to this story.
]]>This article will be a start for series of posts describing how Kubernetes Networking work.
We are now, dealing with more and more environment where there are Kubernetes deployment in play and we should be aware as to where we can perform a packet-capture or look for results in containerized environment.
Let’s get started.
- Pods on a node can communicate with all pods on all nodes without NAT.
- Agents on a node (e.g. system daemons, kubelet) can communicate with all pods on that node.
- Pods in the host network of a node can communicate with all pods on all nodes without NAT.
Now, keeping these fundamentals in check, we will explore how we can solve all the 4 networking issues of Kubernetes.
More information: https://kubernetes.io/docs/concepts/cluster-administration/networking/#the-kubernetes-network-model
Shared volume.
Localhost [Loopback interface].
We created a POD named — busybox, which has 3 containers deployed in it [busybox1, busybox2 and busybox3] .


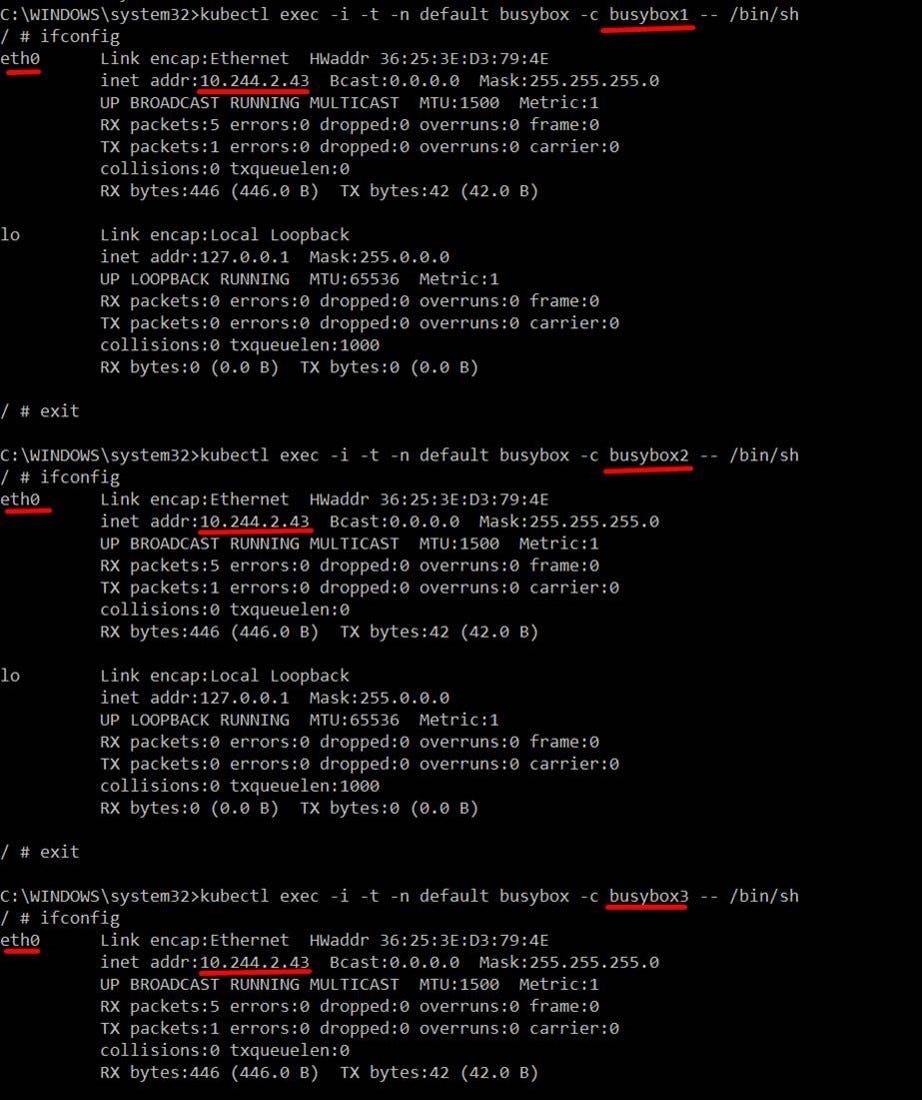
There are total 8 types of Namespaces:
Note: Time namespace is recently added.
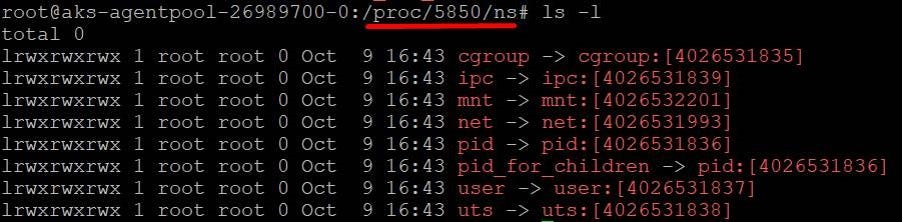
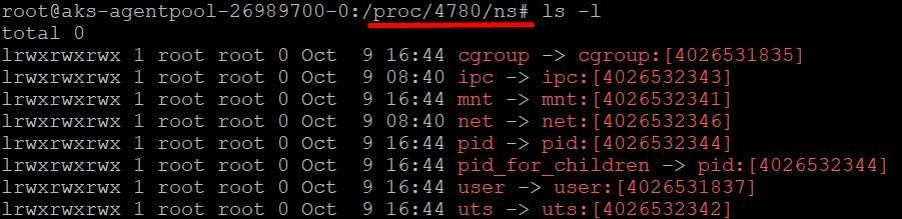
More information:
apiVersion: v1
kind: Pod
metadata:
name: two-containers
spec:
restartPolicy: Never
volumes:
- name: shared-data
emptyDir: {}
containers:
- name: nginx-container
image: nginx
volumeMounts:
- name: shared-data
mountPath: /usr/share/nginx/html
- name: debian-container
image: debian
volumeMounts:
- name: shared-data
mountPath: /pod-data
command: ["/bin/sh"]
args: ["-c", "echo Hello from the debian container > /pod-data/index.html"]


apiVersion: v1
kind: Pod
metadata:
name: new-containers
spec:
restartPolicy: Never
containers:
- name: nginx-container
image: nginx
- name: curl
image: curlimages/curl
command: [ "sleep", "600" ]
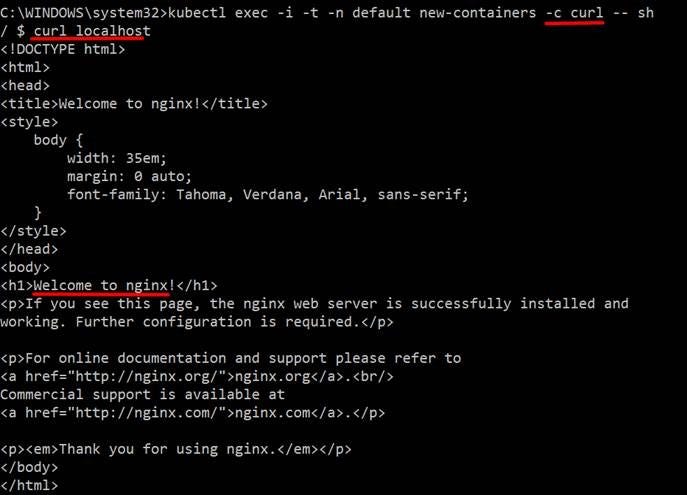
and, this brings us to the end of our first post. :)
In the next post we will discuss on POD to POD communication.
Understanding Kubernetes Networking — Part 1 was originally published in Microsoft Azure on Medium, where people are continuing the conversation by highlighting and responding to this story.
]]>L’invite de commande est l’outil numéro 1 d’un ingénieur informatique. Même s’il n’est au premier abord qu’un outil secondaire pour la plupart des professionnels en début de carrière, il devient, petit à petit, un outil central de leur quotidien.
Disclaimer : Cet article s'adresse surtout aux débutants qui ne voient pas forcément toute l’ampleur que peut avoir une invite de commande dans leur environnement de travail. L’article n’a pas vocation à rentrer dans les détails.
Disclaimer 2 : Les différents exemples de cet article ont été produits depuis la version 32 de Fedora. Ces derniers doivent aussi fonctionner sur toutes les plus grandes distributions Linux et sur macOS. Pour les utilisateurs Windows, il faudra passer par le sous-système Windows pour Linux (WSL).
Généralement, à nos débuts, l’invite de commande sert avant tout à utiliser différentes CLI (Command Line Interface) pour interagir avec d’autres systèmes via des commandes. C’est par exemple le cas de git ou d’aws. À ce stade de l'évolution d’un ingénieur, votre terminal ressemble très certainement à ceci :

Je suis sur la distribution Fedora mais les informations sont généralement les mêmes à savoir le nom d’utilisateur, ici ddoamaral, ainsi que le chemin actuel dans lequel toute commande sera exécutée, ici représenté par un tilde (~). Tilde est un raccourci pour désigner le répertoire Home de l’utilisateur actuel. Dans mon cas, c’est en réalité juste un alias qui représente le chemin /home/ddoamaral/.
Plus le temps passe, plus l'expérience s’accumule et plus l’invite de commande d’un ingénieur devient une application importante et récurrente. Si récurrente qu’elle est aujourd’hui incluse dans la plupart des éditeurs de code. L’invite de commande se transforme alors en gestionnaire de fichiers et de tâches, en éditeur de code, en outil de monitoring. Elle reste très proche de la machine, à contrario des divers autres outils graphiques, ce qui en fait un outil plus fiable et customisable.
Aujourd’hui, nous allons voir certains de ces aspects qui peuvent vous rendre plus productif.
L’invite de commande peut être beaucoup plus qu’un simple outil pour lancer des commandes. Généralement, on fait un tel constat avec le besoin d’avoir des informations contextuelles pour une interface donnée. Voici certains exemples qui vont très certainement vous interpeller :
Il est évident qu’au cours de votre carrière d’ingénieur, vous avez fait/allez faire face à au moins un de ces cas. Fort heureusement, il existe des outils permettant de répondre à cette problématique. Aujourd’hui je vais vous parler d’un ensemble de technologies qui, selon moi, répondent parfaitement à ce besoin. Ainsi, ensemble construisons l’invite de commande 2.0.
Zsh est la base de notre nouvelle invite de commande 2.0. C’est un shell, tout comme bash ou PowerShell. Il a comme principal avantage d’avoir une communauté incroyable ayant développé des outils très complets dont certains vont être présentés aujourd’hui.
Si vous ne l’avez pas encore installé, installez-le depuis cette adresse : https://github.com/ohmyzsh/ohmyzsh/wiki/Installing-ZSH
Une fois cela fait, on peut taper zsh dans l’invite de commande pour changer de shell ou encore chsh puis renseigner /bin/zsh pour faire de ce dernier votre shell par défaut.

Zsh tout seul ne fait pas une grande différence. Il ajoute tout de même de nombreuses fonctionnalités dont certaines sont décrites ici. Il se base sur le même principe que Linux, à savoir commencer avec le strict minimum et par la suite sélectionner les outils qui nous importent.
Oh My Zsh facilite l’installation de ces derniers à travers deux composantes : les plugins et les thèmes. Pour l'installer, c’est tout aussi simple, il suffit de copier coller la commande suivante :
sh -c "$(curl -fsSL https://raw.github.com/ohmyzsh/ohmyzsh/master/tools/install.sh)"
Pour commencer à interagir avec le framework, nous allons tout de suite éditer le fichier .zshrc présent à la racine de notre utilisateur.
À l'intérieur de ce dernier se trouve toute notre configuration zsh. Il faut savoir que toutes les lignes que vous rajouterez dans ce fichier seront exécutées au démarrage de chaque nouvelle invite de commande. Ainsi, si vous rajoutez un echo "Hello ZSH !" au lancement vous obtiendrez une jolie “Hello ZSH !”. Cela vous permet de mettre en place certaines variables d’environnements par exemple. Ainsi, si vous stipulez la ligne suivante : export ENV=1234, vous pouvez utiliser la valeur de la variable d’environnement n’importe où. Les alias sont aussi très intéressants pour gagner du temps. J’utilise par exemple ce dernier pour jump de mon terminal à ma fenêtre visual studio code : alias code.="code . && exit".
On va tout d’abord s'intéresser aux plugins ici. Ces derniers permettent d'ajouter des fonctionnalités à votre console. Dans le fichier .zshrc, on remarque déjà un plugin installé : le plugin git. Ce dernier rajoute énormément d’alias pour gagner du temps lorsqu’on utilise le CLI git. Pour en savoir plus, voici la liste exhaustive de ces derniers : https://github.com/ohmyzsh/ohmyzsh/tree/master/plugins/git. Bien évidemment, on peut ici en rajouter beaucoup plus, qui vont tous rendre votre expérience avec l’invite de commande plus agréable. Ainsi, je ne saurais trop vous conseiller de rajouter au moins les suivants :
a/b/c/d/my-project vous pourrez y accéder via j my-project et pourquoi pas ensuite enchaîner avec votre alias code. pour directement ouvrir votre projet dans visual studio code.cd avec un espace on s’attend par la suite à avoir besoin d’un dossier se trouvant à la racine dans laquelle se trouve l’invite de commande. Pour savoir quels dossiers sont disponibles, on peut tout d’abord lancer la commande ls puis taper le nom précédemment inscrit ou alors on peut saisir la commande cd suivie d’un espace puis appuyer sur la touche SHIFT pour se laisser guider par la console qui va successivement vous présenter toutes les possibilités disponibles. Le plugin en plus de cette fonctionnalité native ajoute le même fonctionnement avec les makefiles, git, etc.
Il existe pléthore d’autres plugins, spécifiques à un certain CLI, ajoutant généralement deux choses : la complétion et des alias. Ainsi si vous utilisez maven, il y a le plugin mvn. Si vous utilisez Kubernetes, il y a le plugin kubectl, etc.
Maintenant que notre invite de commande est intelligente, nous allons la rendre belle et encore plus utile ! C’est à ce moment-là qu’entre en jeu les thèmes et plus particulièrement PowerLevel10k.
On n’oublie pas ce qui nous a amené jusqu’ici, le besoin d’avoir affiché constamment sur notre console des contextes particuliers. On veut savoir sur quelle branche on se trouve lorsqu’on est dans un projet git, on veut savoir dans quel cluster et dans quel namespace on se trouve si on manipule des clusters Kubernetes, etc. Tout ceci va être possible grâce à PowerLevel10k.
Rendez-vous sur ce lien : https://github.com/romkatv/PowerLevel10k.
Protip : n’oubliez pas d’installer aussi la font “meslo-nerd-font-patched-for-PowerLevel10k” pour une expérience utilisateur agréable.
La première fois que vous lancerez votre nouvelle console, vous aurez à customiser votre invite de commande. Si jamais cela ne fonctionne pas, veuillez saisir la commande p10k configure. Dans le cas où vous voulez la même configuration que celle qui va suivre, il vous suffit de dire “yes” pour tous les symboles (normalement il n’y aura pas de problème avec la bonne police d’écriture) puis sélectionnez lean(1) → Unicode(1) → 256 colors(1) → No (1) → Two lines (2) → Disconnected (1) → No frame (1) → Sparse (2) → Many icons (2) → Concise (1) → Yes (y).
Normalement, vous obtiendrez quelque chose de la sorte :

La console n’est plus du tout la même et ce, pour le plus grand plaisir de nos yeux ! Si on décortique les informations ci-dessus, pour l’instant on n’a pas grand chose. On a d’abord un logo, ici Fedora car je suis sur cette distribution. On a ensuite deux segments, chaque segment est généralement caractérisé par deux composants, une icône et une information. Ici, le chemin dans lequel nous nous trouvons à gauche est représenté par une maison et le tilde.
Maintenant plaçons-nous dans un projet utilisant le système git ainsi qu’un environnement virtuel Python particulier. Une fois à l'intérieur, voici à quoi devrait ressembler votre console :

Le voilà le contexte que l’on voulait tant depuis le début. Ici nous avons beaucoup plus d’informations sur notre projet en cours, à savoir l’environnement virtuel utilisé actuellement “article” représenté avec l'icône Python ainsi que les informations sur git, à savoir que l’on est sur la branche master et que la branche a 1 fichier ajouté. Cela fait gagner énormément de temps, plus besoin de git status ou autre !
Il nous reste un dernier contexte que l’on avait mentionné dans l’introduction, le contexte sur le cluster Kubernetes en cours. Il faut taper la commande kubectl pour le voir s’afficher. Vous verrez ainsi apparaître la fameuse barre suivante du nom du cluster, ici le cluster à noeud unique en local minikube. Normalement, ce dernier est succédé d’un “/” suivi du nom du namespace mais comme ce dernier est “default” il est omis par PowerLevel10k.

Cette suite d’outils est selon moi un très bon point d’entrée pour faire connaissance avec votre invite de commande et apprendre à l’apprécier à sa juste valeur. On pourrait bien entendu ne pas s'arrêter là, parler du fuzzy finder, mentionner Vim et son univers bien à lui, parler de taskwarrior qui est selon moi un des meilleurs gestionnaires de tâches, introduire tmux pour avoir plusieurs fenêtres dans la même console. Si vous êtes intéressés par ces derniers, veuillez vous référer à la partie “pour aller plus loin”. Les possibilités sont infinies.
PowerLevel10k est une des pierres angulaires de cette trinité, de plus, il est très facilement customisable. Ainsi nous allons dans une deuxième partie créer nos propres segments PowerLevel10k pour avoir toujours plus d’insight (ce serait vraiment bien de pouvoir monitorer les ressources de son compte AWS depuis notre console 😉).
Dans le texte suivant, je vais souvent aborder la notion de productivité. Cette productivité, je la définis comme étant la quantité de modifications apportées dans une base de code pour un temps donné. J’ai tout à fait conscience que les activités d’un.e développeur.euse ne se limitent pas à écrire du code, et qu’écrire du code en quantité ne rime pas nécessairement avec qualité, ni avec production de valeur pour l’utilisateur. Toutefois, l’interaction avec une base de code reste une activité centrale pour les développeurs.ses, et si Accelerate nous a appris quelque chose, c’est que faire vite peut aussi permettre de faire bien !
![]()
Il y a quelques mois, j’ai décidé de passer d’IntelliJ à Vim en tant qu’outil principal de développement. Parmi les raisons qui m’y ont poussé, je peux citer pêle-mêle :
Et le mur que j’ai pris en pleine figure était à la hauteur de la réputation de Vim ! J’ai eu l’impression de ne plus savoir marcher. Ma connaissance de Vim s’arrêtant à “h,j,k,l” pour me déplacer, “i” et “esc” pour changer de mode et enfin “:wq” pour quitter, la transition fut difficile. Ma productivité s’est effondrée. Chaque modification, même triviale, me prenait un temps énorme. Et l’austérité de Vim out-of-the-box n’aide pas…

Mes premiers jours sur Vim, une allégorie.
Après avoir hésité à abandonner environ 856 fois lors des deux premiers jours, j’ai fini par comprendre que si je voulais continuer d’utiliser Vim, il fallait que je développe un nouveau réflexe. Et mon ambition n’est pas seulement de retrouver ma productivité d’avant, mais de progresser !
Dans Vim, à chaque action “qui gratte”, que je trouve peu fluide, inutilement compliquée ou longue, je prenais quelques dizaines de secondes pour trouver une façon plus efficace de faire, commençant par les actions les plus basiques, pas à pas :
Je fais un aparté ici concernant l’aspect 100% clavier de Vim.
L’argument souvent mis en avant pour justifier l’abandon de la souris est celui de la limitation du changement de contexte : les yeux restent sur l’écran et ne cherchent pas la souris, les bras ne bougent pas, on reste dans le flow sans s’interrompre. Après plusieurs mois de pratique, je suis convaincu que cela apporte effectivement un gain.
Un second argument souvent avancé est la limitation d’une éventuelle fatigue, particulièrement si vous êtes les heureux possesseurs d’un clavier ergonomique. Personnellement, je n’ai pas senti de grande différence à ce niveau là.
Un argument supplémentaire que j’ai rarement vu cité est celui d’une vitesse accrue grâce à la mémoire procédurale, souvent appelée mémoire musculaire. Sur un clavier, la disposition des touches ne change pas. La distance d’une touche à l’autre ne change pas non plus. Et à force de réaliser les mêmes actions, nos muscles vont s’habituer et les réaliser “machinalement”. Evidemment, il est également possible de développer ces automatismes avec l’utilisation d’une souris, toutefois:
Dernier point, la souris a été créée afin de pointer des choses et de permettre l’utilisation de hiérarchies de fenêtres complexes avec une organisation spatiale qui rend la navigation au clavier compliquée. Ce n’est pas le cas de l’édition de texte qui est souvent en 2D, à plat sans trop de complexité hiérarchique.
Après avoir retrouvé un rythme décent sur toutes ces petites actions “unitaires” et appris à “marcher” dans Vim, j’ai continué à appliquer le même reflexe de remise en question et d’apprentissage continu à la suite de mon workflow, pour apprendre à “courir” dans Vim:
Nota: au risque de verser dans le prosélytisme pro-Vim, je peux vous assurer que Vim est très extensible, et qu’énormément des fonctionnalités des IDEs “modernes” sont disponibles via l’écosystème de plugins de Vim !
Au fil des jours et des semaines, j’ai fini par reconstruire toutes les fonctionnalités dont j’avais besoin avec Vim. Cela m’a permis de retrouver, puis dépasser la productivité que j’avais précédemment: pour réaliser des User Stories de complexité et taille similaires, je passais moins de temps à coder qu’avant. Et c’est là que le temps passé, les efforts consentis, toutes les recherches faites commencent à se justifier. En effet, ayant assemblé toutes les fonctionnalités avancées d’un IDE moi-même, j’en connais le fonctionnement en détail et je peux l’adapter. Par exemple :
Et toute cette construction, cette configuration de Vim et de ses plugins, c’est du code ! A la différence d’autres artisans ou artistes (ébénistes, pâtissiers, peintres, etc.) nos outils à nous sont composés de la même “matière”, le code informatique, que celle qu’on travaille. On peut donc appliquer tout notre savoir-faire, toutes les bonnes pratiques que l’on applique quotidiennement sur nos projets à nos outils ! En effet nos outils sont un projet informatique, sur lequel on possède à la fois la casquette de PO, de développeur et d’utilisateur ! Ce code peut et devrait être versionné, refactoré régulièrement pour éviter l’accumulation de dette technique, et doit vivre en même temps que notre workflow par l’ajout et la suppression de fonctionnalités. Et on doit avoir le même niveau d’exigence vis-à-vis du code de nos outils que dans nos projets.
Cette prise de conscience (être critique et exigeant vis-à-vis de nos outils qui ne sont finalement “que” du code) ne doit bien évidemment pas s’arrêter à nos IDEs. Notre travail ne s’effectue pas intégralement dans notre IDE. Toutes les actions que l’on réalise peuvent être améliorées pour plus d’efficacité : utiliser un raccourci facilement et rapidement accessible pour ouvrir notre IDE directement avec le bon fichier, comment on trouve le bon fichier, comment on interagit avec nos outils de communication, etc. Toutes ces actions font également partie de notre workflow et sont réalisées avec des outils informatiques. On peut donc également chercher à les optimiser !
Pour moi, c’est encore une fois via Vim et ses extensions que cette prise de conscience a eu lieu. A force d’utiliser FZF dans Vim, j’ai fini par coder quelques alias pour m’aider à utiliser le terminal plus efficacement. Puis, une chose en entraîna une autre… Prenons l’exemple tout simple du choix d’une branche Git. Initialement, mon workflow ressemblait à ça:
Maintenant, il me suffit d’exécuter “gco” pour voir la liste des branches apparaître. Je peux sélectionner une branche via les flèches du clavier ou taper quelques caractères du nom de la branche (via de la recherche approximative), un appui sur entrée et c’est fini. Tout ça sans quitter le clavier des mains, et l’écran des yeux. Il me faut rarement taper plus de 6-7 caractères + 1 appui sur entrée pour arriver au résultat recherché.
Autre exemple, mes déplacements dans le terminal ont été énormément fluidifiés et accélérés par l’utilisation de z. Plus besoin de taper sur tab 5 ou 10 fois pour utiliser l’auto-complétion de cd quand vous voulez aller au fond de votre filetree. La majorité du temps, je tape les 5-6 premiers caractères du dossier que je cherche, j’appuie sur entrée et je suis exactement où je souhaite être.
Toutefois, comme mentionné en introduction, les tâches d’un.e développeur.euse ne se limitent pas non plus à l’édition de code ! Voici deux exemples supplémentaires, inspirés par des collègues, pour montrer que les bonnes pratiques décrites dans cet article s’appliquent plus largement:
Encore une fois, tout ça n’est “que” du code. Et vous pouvez donc le versionner, le refactorer, etc. On entre là dans le monde des dotfiles ! Nommés ainsi parce que sur les systèmes Unix, les fichiers de configuration sont généralement trouvés dans le /home/ et préfixées d’un point “.”, “dot” en anglais, ce terme regroupe ainsi tous les fichiers de configuration des outils que vous utilisez. Votre configuration Vim ? Vos alias bash ? La configuration de votre linter ? Les variables d’environnements pour ripgrep ? Tout ça, c’est dans vos dotfiles. Et c’est du code.

Les dotfiles, intimement liés à votre workflow
Il peut être intéressant de modulariser certaines configurations. Par exemple, si vous avez des alias spécifiques à votre projet actuel, il peut être intéressant de les consigner dans un fichier à part plutôt que directement dans votre ~/.bashrc. Cela vous permettra de faire le tri de vos alias beaucoup plus facilement quand vous changerez de projet !
Beaucoup de gens partagent leurs dotfiles. Étant moi-même peu imaginatif, la lecture des dotfiles d’autres personnes me permet souvent de trouver des idées d’amélioration, des solutions à mes problèmes auxquelles je n’avais pas pensé, enfin bref de trouver de l’inspiration ! Beaucoup de bonnes idées sont aussi nées d’échanges avec des collègues !
On peut même aller encore plus loin que les dotfiles. Si vous savez que vous rejoignez un projet pour un certain temps, il peut être intéressant de regrouper certaines fonctionnalités avancées dans un outil CLI dédié. On peut par exemple imaginer un outil CLI développé dans votre langage favori (en Python par exemple) pour gérer votre environnement de dev si celui est complexe:
Cette dernière suggestion peut être redondante avec une pratique plus largement répandue d’utiliser un Makefile pour réaliser ce genre d’actions. L’avantage du Makefile, c’est qu’il est généralement inclus au code du projet, et donc accessible et commun à tous les membres du projet. Le débat “make ou outil CLI” dépasse le cadre de cet article, retenez simplement que plusieurs approches existent, et que l’objectif recherché est le même: simplifier et accélérer au maximum toute action que vous allez être amenés à répéter régulièrement !
Alors évidemment, aucune de ces suggestions prise indépendamment ne va changer votre vie, j’en suis bien conscient. Toutefois, leur impact est important pour plusieurs raisons:
Bref, les gains liés à des outils adaptés sont notables, mais combien de temps faut-il “investir” pour en arriver là ? En supposant qu’on investisse 1 heure/semaine à travailler sur ses outils et qu’à la fin de la semaine, cela nous permet de gagner ~5min/jour, soit 25min/semaine, en 3 semaines on aura suffisamment amélioré sa productivité pour rentabiliser cette heure allouée aux outils ! Après tout, on dédie du temps à l’amélioration continue dans tous nos projets, pourquoi en serait-il autrement pour nos outils ?

Reculer pour mieux sauter: mon passage à Vim résumé en une image
Mais le temps gagné est loin d’être le seul intérêt d’investir dans ses outils !
Et en bonus, comme tout est versioné, il est facile de porter sa configuration sur un autre poste (son poste personnel, le poste du client final quand on fait du conseil, sa nouvelle machine fraîchement déballée, etc) !
J’espère vous avoir fait comprendre l’intérêt d’investir du temps et de l’énergie dans vos outils ! Prenez le temps d’apprendre à vous servir efficacement de vos outils, privilégiez des outils que vous pouvez facilement modifier, étendre, interconnecter. Vous avez la chance de pouvoir façonner les outils que vous utilisez à votre guise, de les adapter à vos besoins et à vos envies. Profitez-en ! Vous en sortirez plus efficaces dans ce que vous faites tous les jours, et cela ouvrira vos horizons sur plein de nouveaux sujets.
]]> Evalandgo est une solution qui permet de créer un questionnaire ou un quiz en ligne facilement. Cette solution française et RGPD compliant s'adapte à tous les besoins professionnels. Tour d'horizon des fonctionnalités de la plateforme.
Evalandgo est une solution qui permet de créer un questionnaire ou un quiz en ligne facilement. Cette solution française et RGPD compliant s'adapte à tous les besoins professionnels. Tour d'horizon des fonctionnalités de la plateforme.
L'article Evalandgo : la solution de référence pour créer des questionnaires et des quiz en ligne a été publié sur BDM.
]]> La BattleDev est de retour le 26 novembre prochain. Inscrivez-vous et affrontez plus de 5 000 développeurs en ligne !
La BattleDev est de retour le 26 novembre prochain. Inscrivez-vous et affrontez plus de 5 000 développeurs en ligne !
L'article BattleDev : inscrivez-vous à la plus grande compétition de code en ligne de France a été publié sur BDM.
]]>
Votre équipe se plaint régulièrement que l’US dans le Sprint n’est pas prête ? Vous assistez régulièrement à des redéfinitions des US en cours de Sprint ? Vous voulez remettre de l’ordre là-dedans ? Il est temps de mettre en place votre Definition Of Ready (DOR) ! Ce qui est cool, c’est que l’exercice est valable aussi pour faire la Definition of Done (DOD) !
Je vous propose un mode opératoire sous forme de retour d’expérience que j’ai pu animer en tant que Scrum Master et comme on n’aime pas passer du temps en réunion, on va rythmer ça et envoyer le paquet en 30 minutes.
Objectif :
À 11h30, l’atelier commence après seulement 7 minutes de rappel pour que toutes les personnes présentes arrivent.
J’ai fait 2 équipes (nous sommes 10) avec 1 jeu dans chaque. J’ai veillé à ce que les compétences soient équitablement réparties entre les 2 groupes.
Dans une première phase, chaque équipe a classé les cartes en 3 catégories :
Un point à rappeler au début de l’atelier une DOR, comme une DOD (Definition Of Done) n’est pas un objectif que l’on tente d’atteindre, c’est un engagement. J’apprécie ces artefacts, ils permettent de clairement décrire comment nous fonctionnons, d’améliorer le flux et de garantir la qualité applicative en production.
Les 2 équipes ont au cours de la séance demandé à ajouter une colonne « Peut-être ». Magnanime, cela a été accordé (et elle est dans l’atelier de base).
Cette phase avait un time box de 10 minutes, elle a donc duré 12 minutes.
Il ne faut pas hésiter à modifier le wording des cartes pour qu’il s’adapte bien à votre contexte. De base, c’est assez générique.
Dernière étape, on a fait un dernier tour pour voir s’il n’y avait rien qu’on aurait aimé ajouter et qui aurait été absent du paquet de cartes. On en a ajouté une : « les définitions d’interface des Web Services dont nous dépendons pour l’US doivent être à jour et disponibles ».
Avant de conclure la séance sur un ROTI de 6/5, je pense qu’il est important de rappeler que la Definition Of Ready n’est pas le contrat de service des POs mais que l’équipe entière doit participer à ce qu’elle soit validée pour chaque US.
En seulement 30 minutes, l’objectif a été atteint avec 4 items à vérifier.
Chaque item a un vrai sens et apporte des nouvelles pratiques à l’équipe.
Ce format est facilement adaptable en remote sur un outil type Miro ou draft.io, on crée les 3 colonnes, « Oui », « Non », « Peut être ». On place les images du tas de carte à côté et on les dépile ensemble selon la même procédure .
Il faut vraiment trouver une formation soft-skills découpage (avec spécialisation en coins ronds) pour Axel ! Blague à part, le format relativement court et le fait qu’on en sorte les items « auxquels il faut prêter attention / qu’on veut commencer à faire » a permis d’éviter de se retrouver dans une tentative de DOR exhaustive à 25 items en 2h, ce qui est plutôt cool et pragmatique. On sait qu’à partir des outputs de cet atelier on tendra à s’améliorer.
J’ai été assez surpris de voir que la quasi-totalité des items dans « Oui » étaient communs aux deux groupes. Je pensais qu’il y aurait plus de divergence dans l’interprétation des cartes et du coup dans celles choisies. Comme quoi le wording est le bon j’imagine ! En revanche les « catégories » de cartes apportaient relativement peu de valeur j’ai trouvé, ou en tout cas on ne les a pas exploitées. Mais ça fait plus joli sur les cartes, donc bon. Bref, plutôt cool et efficace d’un point de vue participant.
April 28, 2020 | Download a PDF of this article
More quiz questions available here
If you have worked on our quiz questions in the past, you know none of them is easy. They model the difficult questions from certification examinations. The “intermediate” and “advanced” designations refer to the exams rather than to the questions, although in almost all cases, “advanced” questions will be harder. We write questions for the certification exams, and we intend that the same rules apply: Take words at their face value and trust that the questions are not intended to deceive you but to straightforwardly test your knowledge of the ins and outs of the language.
The objective here is to use Java control statements including if, if/else, and switch.
Given this class:
public class WeirdSwitch { public static void main(String[] args) { byte b = 3; int i = 0; switch(b) { case 3 | 4 : i = i + 4; // line n1 case 2 | 3 : i = i + 2; } System.out.println(i); } }What is the result? Choose one.
A. 0 B. 2 C. 4 D. 6 E. Compilation fails at line n1.Answer. Perhaps the most striking part of the code in this question, and certainly the key to correctly evaluating its behavior, is the use of the vertical bar character (|) in the case clauses. In some languages (for example, Scala), this creates a list of alternative matches. However, in Java, that’s not the behavior. The meaning of the single vertical bar operator is a bitwise OR operation. Thus, the effect of the expressions 3 | 4 and 2 | 3 are very specific, but single, values.
To understand what these case labels represent, you need to look at the underlying binary representation of the numbers and see how the bitwise OR operation works. The binary representations of 2, 3, and 4 are shown in Table 1.

Table 1. Decimal versus binary representations
Remember that Java has a binary literal format, which uses the prefix 0b, so you can represent these numbers directly as binary literals in Java as the numbers 0b0010, 0b0011, and 0b0100, respectively.
Performing the bitwise OR operation produces a 1 bit in the result if there is a 1 bit in the corresponding column in either of the operands. Therefore 3 | 4 produces this:
0011 0100 ------ 0111The 0b0111 is the value 7 decimal.
Similarly, you can compute 2 | 3 as this:
0010 0011 ------ 0011Notice that this creates a result of 3.
Code with the values of the constant expressions 3 | 4 and 2 | 3 replaced by the values those expressions actually evaluate to looks like this:
byte b = 3; int i = 0; switch(b) { case 7 : i = i + 4; // line n1 case 3 : i = i + 2; }Now, you can clearly see that the behavior of the code will be that the first case does not match because 3 is not equal to 7. However, the second case does match, and the value of i is incremented by 2 (becoming 2). Then the switch block ends and the 2 is printed to the screen. From this, you can see that the code will successfully compile and print 2. Therefore, option B is correct, and options A, C, D, and E are incorrect.
Option C warrants a moment of discussion, even though we’ve already eliminated it. It’s worth considering that in a multiple-choice exam, the wrong answers (which are called “distractors” in the testing trade) are usually chosen to represent what you might think was right if you have a common misunderstanding or make a common error.
In option C, it’s worth observing that there’s no possibility of this type of code printing 4. This is because of the fall-through behavior of Java’s switch statement. In the absence of a break statement in this construction, if the code incremented by 4 (by matching the first case pattern), it would continue and execute the code that also increments by 2. Therefore, an output of 4 is never possible with this code. The value of i will be 6, 2, or 0. Of course, if those who don’t know how break works (and that statement is necessary in Java) try to answer this question, they might be fooled into thinking that 4 is a possible output.
The correct answer is option B.
]]>J'aime les tests ! Les designs qu'ils font émerger, les refactorings qu'ils sécurisent et la vélocité qu'ils permettent d'atteindre.
Quand on fait des tests, on cherche à tester ce que l'on fait, pas comment on le fait. Tester les détails d'implémentation est le meilleur moyen de se fâcher avec ces validations automatiques et immédiates de notre code.
Dans ce cadre, on peut légitimement se demander s’il faut tester les logs. C'est vrai, c'est un simple détail d'implémentation, un outil de debugging en prod, non ?
Il arrive que nos applications ne se comportent pas comme on s'y attendrait en production. Ce fameux cas qui ne peut pas arriver, auquel on n’a pas pensé et que l'on rencontre au premier clic d'un VIP.
Ces innombrables démonstrations de la loi de Murphy suffisent à elles seules à faire attention à avoir des traces les plus exploitables possibles.
Avoir des logs parlants, clairs, qui permettent une analyse simple du problème rencontré tout en respectant la RGPD demande bien souvent du code effectuant des traitements spécifiques. Au même titre que tout traitement, il est pertinent de vouloir les tester !
Si vous passez du temps à avoir des logs propres, ce n'est certainement pas pour que leur création lève une exception et empire la situation que vous étiez en train d'analyser. Enfin, ça c'est dans le pire des cas, mais des logs tout simplement inexploitables ne sont pas non plus une bonne idée.
On pense souvent aux logs quand ça ne va pas mais les logs quand tout va bien peuvent aussi être intéressants :
Une fois que nos logs sont propres, on peut les exploiter, par exemple en créant des alertes automatiques pertinentes.
Même s'ils ne font pas directement de traitements métier, les logs ne sont pas un détail d'implémentation. Ils font partie intégrante de la solution et doivent faire l'objet de la même attention que tout le reste du code !
Avec Junit 5 et la mécanique d'extensions il est très simple d'écrire une extension qui nous permettra la validation de nos logs :
import static org.assertj.core.api.Assertions.*;
import ch.qos.logback.classic.Level;
import ch.qos.logback.classic.Logger;
import ch.qos.logback.classic.spi.ILoggingEvent;
import ch.qos.logback.core.read.ListAppender;
import java.util.function.Predicate;
import org.junit.jupiter.api.extension.AfterEachCallback;
import org.junit.jupiter.api.extension.BeforeEachCallback;
import org.junit.jupiter.api.extension.ExtensionContext;
import org.junit.jupiter.api.extension.ParameterContext;
import org.junit.jupiter.api.extension.ParameterResolutionException;
import org.junit.jupiter.api.extension.ParameterResolver;
import org.slf4j.LoggerFactory;
public final class LogSpy implements BeforeEachCallback, AfterEachCallback, ParameterResolver {
private Logger logger;
private ListAppender<ILoggingEvent> appender;
@Override
public void beforeEach(ExtensionContext context) throws Exception {
appender = new ListAppender<>();
logger = (Logger) LoggerFactory.getLogger("com.company.application");
logger.addAppender(appender);
logger.setLevel(Level.TRACE);
appender.start();
}
@Override
public void afterEach(ExtensionContext context) throws Exception {
logger.detachAppender(appender);
}
public void assertLogged(Level level, String content) {
assertThat(appender.list.stream().anyMatch(withLog(level, content))).isTrue();
}
public void assertLogged(Level level, String content, int count) {
assertThat(appender.list.stream().filter(withLog(level, content)).count()).isEqualTo(count);
}
public void assertNotLogged(Level level, String content) {
assertThat(appender.list.stream().noneMatch(withLog(level, content))).isTrue();
}
private Predicate<ILoggingEvent> withLog(Level level, String content) {
return event -> level.equals(event.getLevel()) && event.toString().contains(content);
}
@Override
public boolean supportsParameter(ParameterContext parameterContext, ExtensionContext extensionContext)
throws ParameterResolutionException {
return parameterContext.getParameter().getType().equals(LogSpy.class);
}
@Override
public LogSpy resolveParameter(ParameterContext parameterContext, ExtensionContext extensionContext) throws ParameterResolutionException {
return this;
}
}
Attention : pensez bien à changer le package "com.company.application" dans la définition du logger de tests !
On pourra alors utiliser cette extension dans nos tests :
@ExtendWith(LogSpy.class)
class MyAwsomeUnitTest {
private final LogSpy logs;
public MyAwsomeUnitTest(LogSpy logs) {
this.logs = logs;
}
@Test
void shouldDoSomethingCool() {
// ...
logs.assertLogged(Level.WARN, "something not intended happens");
}
}
Le fonctionnement de l'extension est très simple : on ajoute un logger en niveau TRACE qui log dans une list. On peut alors très simplement vérifier les éléments dans la liste et faire les assertions que l'on souhaite. Vous avez quelques exemples ici mais n'hésitez pas à ajouter les vôtres !
Non ! Comme pour tout, le but n'est pas de tout tester : "I get paid for code that works, not for tests" - Kent Beck.
Les tests doivent vous aider, vous faire gagner du temps. Testez vos logs si vous en ressentez le besoin. Avec le temps, étrangement, vous ressentirez de plus en plus ce besoin, enfin, vous ferez ces tests sans y penser et sans y consacrer d'énergie, mais ça, c'est une autre histoire.
]]>IndieHosters lance une nouvelle solution collaborative open source. Liiibre entend donner accès aux "meilleurs outils libres pour collaborer en ligne".

Liiibre est une solution en ligne destinée aux organisations allant d'une dizaine à plusieurs centaines de personnes et spécialisée dans la collaboration en ligne. Elle entend remplacer des outils comme Microsoft 365, GSuite, Slack, Teams, etc.
Elle a été lancée par le collectif IndieHosters.
La solution Liiibre comprend des outils collaboratifs de base, pour tout type de projets :
 Stockage de données avec une instance de Nextcloud ;
Agenda partagé ;
Édition de documents (collaborative) avec OnlyOffice ;
Messagerie instantanée grâce à Rocketchat ;
Visioconférence avec Jitsi Meeting ;
Applications mobiles ou tablettes pour iOS, iPadOS et Android : Nextcloud, Only Office,Rocketchat, Jitsi.
Stockage de données avec une instance de Nextcloud ;
Agenda partagé ;
Édition de documents (collaborative) avec OnlyOffice ;
Messagerie instantanée grâce à Rocketchat ;
Visioconférence avec Jitsi Meeting ;
Applications mobiles ou tablettes pour iOS, iPadOS et Android : Nextcloud, Only Office,Rocketchat, Jitsi.
La solution est extensible sur simple demande : vous pouvez ajouter des outils tels que CodiMD, Wekan, Draw et MediaWiki.
L'idée derrière Liiibre est la possibilité de "reprendre le contrôle" sur ses données, avec plusieurs avantages :
Les outils sont sous licence libre ou open source, vous êtes libre de migrer Liiibre chez un autre hébergeur ou sur vos propres serveurs à tout moment ;
Aucune exploitation des (méta-)données ;
Hébergement sécurisé localisé à Falkenstein, en Allemagne, opéré par Hetzner ;
Possibilité de chiffrer les données en utilisant Cryptomator.
Vous trouverez toutes les informations pratiques sur Liiibre sur le site officiel du projet. Un formulaire est disponible pour vous lancer sur cette page.
Hébergement Nextcloud en France : c'est désormais possible chez Gandi
Jitsi Meet, une alternative open source à Zoom Cloud Meeting
OnlyOffice encore un peu mieux connecté à Nextcloud
Janvier 1983 : Apple présentait officiellement le LISA.
Un micro-ordinateur incroyable : écran bitmap haute résolution, 1 Mo de RAM, disque dur en standard, souris, processeur Motorola 68000, système graphique, suite logicielle intégrée ! Un an avant le Macintosh. L’origine de la machine remonte à fin 1978. Steve Jobs va poser les bases du futur LISA avant d’être viré du projet.
Le magazine Technosaures revient sur l’histoire incroyable de cette machine : son développement, les conflits, les développeurs clés, les problèmes techniques qui ralentissent le projet, la création de l’interface graphique, pourquoi et comment le lecteur twiggy sera remplacé par le Sony 3 1/5, les petits détails qui font toute la différence, etc.
Machine exceptionnelle, magazine exceptionnel ! Technosaures n°4 est disponible en deux éditions :
- édition standard 52 pages
- édition deluxe 84 pages
Un voyage dans la temps et la technologie à ne pas rater !
Retrouvez tous les numéros de Technosaures dans notre boutique en ligne

render() est appelée et l'ensemble des sous composant sont rendu à nouveau. Il est cependant possible de mémoriser le rendu d'un élément afin d'éviter les rendu consécutif si ses propriétés et son état n'a pas changé depuis le dernier rendu. Il existe 2 méthodes pour "mémoiser" un composant :
Si votre composant est une fonction il suffit d'utiliser la fonction React.memo...
In this part, we will run the Java EE app as a Docker container on Azure Container Instances. The example used in the blog post is a simple three-tier application that uses Java EE 8 specifications, such as JAX-RS, EJB, CDI, JPA, JSF, Bean Validation. We will use the Payara Server to deploy the application and use PostgreSQL as the relational database.
]]>Les instructions de cet exercice sont disponible sur la documentation de React
React est une librairie qui va vous permettre de représenter une interface à l'aide d'élément qui vont être capable d'évoluer en fonction des changements d'état de votre application. Pour mieux comprendre cette approche prenons un exemple concret d'interface Web basée sur la manipulation du DOM...
L'objectif de cet exercice est de créer une fonction Spanify() qui permettra de créer un effet d'animation mot par mot. L'objectif ce cette fonction est de convertir la structure HTML du titre.
<h1>Ceci est <strong>un titre</strong></h1>
En entourant chaque mot d'une <span>....
1) Enable async processing in Spring Boot by annotation Spring Boot Application class with @EnableAsync
[Curious about the Raspberry Pi single-board computer? A few months ago, Java Magazine contributor Alexa Weber Morales wrote an excellent overview, “Why Oracle Engineers Love Raspberry Pi Projects.” —Ed.]
The Raspberry Pi single-board computer is the ideal starting point if you want to experiment with electronic components. And if you can combine this inexpensive hardware with the software tools Java developers use every day, a new world opens for you. The first time I had a blinking LED controlled by Java was a true aha moment.
This article walks you through building a JavaFX dashboard-style application using Gerrit Grunwald’s TilesFX library. Figure 1 shows the user interface.

Figure 1. JavaFX application’s user interface
You can also view a video of this application running on a Raspberry Pi 3B+ board. That video also demonstrates a touchscreen interface.
The code and techniques used in this article are valid only for Raspberry Pi computers with an ARM v7 or ARM v8 processor. In the Raspberry Pi specifications table on Wikipedia, you can get a clear overview of the boards available with this type of processor:
You can find the other electronic components that are used in this project in most Arduino/Pi starter kits. But if you have some other components you want to use, you can start with the components I used for this project and adapt them to your needs. These are the components I used:
If you start from scratch with a new Raspberry Pi board, prepare an SD card with an operating system. This project uses the full Raspbian OS. Download the imager tool. The version 1.2 imager I used was released March 2020 (see Figure 2 and Figure 3). Be sure to select Raspbian Full.

Figure 2. Download site for the imager tool

Figure 3. Choose the Raspbian Full option for the OS.
When the SD card is ready, put it in the Raspberry Pi, launch the operating system and go through the steps to configure it and to connect to your Wi-Fi network.
Install the JDK with JavaFXThe Raspbian release notes indicate that the version I’m using, 2019-06-20, includes OpenJDK Java 11.
2019-06-20: * Based on Debian Buster * Oracle Java 7 and 8 replaced with OpenJDK 11You can see the Java version:
$ java -version openjdk version "11.0.3" 2019-04-16 OpenJDK Runtime Environment (build 11.0.3+7-post-Raspbian-5) OpenJDK Server VM (build 11.0.3+7-post-Raspbian-5, mixed mode)The board is now good to run any Java 11–based program. But because JavaFX is no longer part of the JDK (since Java 11), running a JavaFX program on Raspberry Pi will not work out of the box.
Luckily, BellSoft provides the Liberica JDK. The version dedicated for the Raspberry Pi includes JavaFX, so you will be able to run a packaged JavaFX application with the simple java -jar yourapp.jar start command. Use the download link from BellSoft to install an alternative JDK, like this:
$ cd /home/pi $ wget https://download.bell-sw.com/java/13/bellsoft-jdk13-linux-arm32-vfp-hflt.deb $ sudo apt-get install ./bellsoft-jdk13-linux-arm32-vfp-hflt.deb $ sudo update-alternatives --config javac $ sudo update-alternatives --config javaWhen this is done, check the version again and it should look like this:
$ java --version openjdk version "13-BellSoft" 2019-09-17 OpenJDK Runtime Environment (build 13-BellSoft+33) OpenJDK Server VM (build 13-BellSoft+33, mixed mode)On my test Pi board, I even keep different versions of Liberica JDK. Switching between the versions is very easy using the update-alternatives command (see Figure 4).

Figure 4. Switching between Liberica JDK versions
On GitHub, in the source code’s Chapter_04_Java/scripts folder, you can find installation scripts for multiple versions of Liberica JDK. Those contain the correct download link for each version. See Figure 5.

Figure 5. Scripts for Liberica JDK versions
Different Raspberry Pi numbering schemesBefore connecting the components to the board’s GPIO (general-purpose input/output) connectors, stop to consider the three numbering schemes used to identify the pins. It can be confusing to work with the GPIO connectors. Refer to the comprehensive GPIO pinout guide for in-depth information, but here’s a brief summary.
Header pin number. This is the logical number in the header. One row has all the even-numbered pins and another row has all the odd-numbered pins. See Figure 6.

Figure 6. Pin numbering in the header
BCM number. This refers to the Broadcom channel number, which is the numbering inside the chip that is used on the Raspberry Pi.
WiringPi number. WiringPi is the underlying framework used by Pi4J (which I use as the library in the Java project) to control the GPIOs. This different numbering scheme has a historical reason. When development for the very first Raspberry Pi boards was still ongoing, only eight pins were foreseen. But when the designs further evolved and more pins were added, the numbering in WiringPi was extended to be able to address the extra pins.
To make it easier for Java developers to understand the difference between the different header types, pins, and functionalities, I created a small library that you can find in the Maven repository at be.webtechie.pi-headers. By using this library and a small JavaFX application, I created the overview image shown in Figure 7 to make it easy to find and match a number to the appropriate pin on the board. For more information, see “Raspberry Pi history, versions, pins and headers as a Java Maven library.”

Figure 7. Matching numbers to pins on the board
Connect the hardwareLet’s add some hardware to use some of the full power of the Pi board: an LED, a push button, and a distance sensor. See Table 1, Figure 8, and Figure 9.

Table 1. Mapping pins to the appropriate devices

Figure 8. Physical wiring

Figure 9. Wiring schematic
Figure 10 shows my setup using a RasPiO breadboard bridge, which makes it easier to find the correct pin. The bridge connector puts the BCM numbers in logical order, but I still use a separate breadboard to have a bit more space. Portsplus offers a similar handy board.

Figure 10. Photo of the setup on a RasPiO breadboard bridge
To test whether the LED is connected in the correct direction for its polarity, unplug the cable between the LED and the GPIO pin (the orange cable in Figure 10) and connect it directly to the 3.3V pin (or the + row on the breadboard). If the LED doesn’t turn on, you need to swap its direction.
Test the LED and button from the terminalTo test the connections, run the gpio command via the terminal.
Important note: If you are using a Raspberry Pi 4 board, be sure to use version 2.52 of the gpio utility. Because the internal wiring of the processor on the Pi 4 board is different from the previous boards, an update is available for the utility, if needed. Check your version by using the gpio -v command via the terminal and, if needed, install the new version using the following commands:
$ gpio -v gpio version: 2.50 $ cd /tmp $ wget https://project-downloads.drogon.net/wiringpi-latest.deb $ sudo dpkg -i wiringpi-latest.deb $ gpio -v gpio version: 2.52Turn the LED on (1) and off (0):
$ gpio mode 29 out $ gpio write 29 1 $ gpio write 29 0Read the button state (1 = pressed, 0 = not pressed) of WiringPi pin 27:
$ gpio mode 27 in $ gpio read 27 1 Toggle the LED with JavaNow the real fun begins! The following code configures WiringPi pin 29 and toggles it 10 times between on and off, with an interval of 500 milliseconds, using the same command I used before in the terminal. Create a file named HelloGpio.java that contains the following:
public class HelloGpio { public static void main (String[] args) { System.out.println("Hello Gpio"); try { Runtime.getRuntime().exec("gpio mode 29 out"); var loopCounter = 0; var on = true; while (loopCounter < 10) { System.out.println("Changing LED to " + (on ? "on" : "off")); Runtime.getRuntime().exec("gpio write 29 " + (on ? "1" : "0")); on = !on; Thread.sleep(500); loopCounter++; } } catch (Exception ex) { System.err.println("Exception from Runtime: " + ex.getMessage()); } } }Since the code will use Java 11 (or higher), the Java file can be executed without compilation:
$ java HelloGpio.java Hello Gpio Changing LED to on Changing LED to off Changing LED to on … Introducing the distance sensorThe example application for this article uses a common ultrasound distance sensor that you can find in many starter kits for Arduino and Pi. It is a module known as HC-SR04; you can find more information and examples online. The module needs both input and output GPIO connections. This sensor works the same way as the system used by a bat to fly in the dark without hitting walls: It uses the reflection of ultrasound to calculate the distance to an object off which the sound reflects.
Measuring a distance requires the example application and the module to perform these steps:
Running one Java file is good for testing the setup, but it is only a first step. The example application here uses the Pi4J library as the connection between Java and the GPIO ports on the Raspberry Pi board. Pi4J needs to be installed on the Raspberry Pi and can be integrated in the Java application with a Maven dependency. You can find the full source code for this example application on GitHub.
The following Maven dependencies are specified in a limited POM file:
Here are the classes for interacting with the hardware.
GpioHelper class. All the functionality related to the GPIO ports is grouped in this class. It starts with the definition of the pins to which the hardware components are connected and the initialization of the Pi4J GpioController. Extended functionality is handled in separate classes: ButtonChangeEventListener and DistanceSensorMeasurement (described shortly). Additional methods and getters will be used by the UI later.
public class GpioHelper { private static final Logger logger = LogManager.getLogger(GpioHelper.class); /** * The pins being used in the example. */ private static final Pin PIN_LED = RaspiPin.GPIO_29; // BCM 21, Header pin 40 private static final Pin PIN_BUTTON = RaspiPin.GPIO_27; // BCM 16, Header pin 36 private static final Pin PIN_ECHO = RaspiPin.GPIO_05; // BCM 24, Header pin 18 private static final Pin PIN_TRIGGER = RaspiPin.GPIO_01; // BCM 18, Header pin 12 /** * The connected hardware components. */ private GpioController gpioController; /** * The Pi4J GPIO input and outputs. */ private GpioPinDigitalOutput led = null; /** * The GPIO handlers. */ private ButtonChangeEventListener buttonChangeEventListener = null; private DistanceSensorMeasurement distanceSensorMeasurement = null; /** * Constructor. */ public GpioHelper() { try { // Initialize the GPIO controller this.gpioController = GpioFactory.getInstance(); // Initialize the LED pin as a digital output pin with an initial low state this.led = gpioController.provisionDigitalOutputPin(PIN_LED, "RED", PinState.LOW); this.led.setShutdownOptions(true, PinState.LOW); // Initialize the input pin with pulldown resistor GpioPinDigitalInput button = gpioController .provisionDigitalInputPin(PIN_BUTTON, "Button", PinPullResistance.PULL_DOWN); // Initialize the pins for the distance sensor and start thread GpioPinDigitalOutput trigger = gpioController.provisionDigitalOutputPin(PIN_TRIGGER, "Trigger", PinState.LOW); GpioPinDigitalInput echo = gpioController.provisionDigitalInputPin(PIN_ECHO, "Echo", PinPullResistance.PULL_UP); this.distanceSensorMeasurement = new DistanceSensorMeasurement(trigger, echo); ScheduledExecutorService executorService = Executors.newSingleThreadScheduledExecutor(); executorService.scheduleAtFixedRate(this.distanceSensorMeasurement, 1, 1, TimeUnit.SECONDS); // Attach an event listener this.buttonChangeEventListener = new ButtonChangeEventListener(); button.addListener(this.buttonChangeEventListener); } catch (UnsatisfiedLinkError | IllegalArgumentException ex) { logger.error("Problem with Pi4J! Probably running on non-Pi-device or Pi4J not installed. Error: {}", ex.getMessage()); } } public GpioController getGpioController() { return this.gpioController; } /** * Set the state of the LED. * * @param on Flag true if the LED must be switched on */ public void setLed(boolean on) { if (this.led != null) { if (on) { this.led.high(); } else { this.led.low(); } } } /** * Get the data from the button. * * @return {@link XYChart.Series} */ public XYChart.Series<String, Number> getButtonEvents() { if (this.buttonChangeEventListener != null) { return this.buttonChangeEventListener.getData(); } else { return new Series<>(); } } /** * Get the data from the distance measurement. * * @return {@link XYChart.Series} */ public XYChart.Series<String, Number> getDistanceMeasurements() { if (this.distanceSensorMeasurement != null) { return this.distanceSensorMeasurement.getData(); } else { return new Series<>(); } } }ButtonChangeEventListener class. Because this class implements the Pi4J GpioPinListenerDigital, it can handle the button change and store the change in an XYChart.Series with the time stamp.
@Override public void handleGpioPinDigitalStateChangeEvent(GpioPinDigitalStateChangeEvent event) { var timeStamp = LocalTime.now().format(DateTimeFormatter.ofPattern("HH.mm.ss")); this.data.getData().add(new XYChart.Data<>(timeStamp, event.getState().isHigh() ? 1 : 0)); logger.info("Button state changed to {}", event.getState().isHigh() ? "high" : "low"); }DistanceSensorMeasurement class. This class is a Runnable that adds the measured distance to a similar data series with the time stamp for each run.
@Override public void run() { // Set trigger high for 0.01 ms this.trigger.pulse(10, PinState.HIGH, true, TimeUnit.NANOSECONDS); // Start the measurement while (this.echo.isLow()) { // Wait until the echo pin is high, indicating the ultrasound was sent } long start = System.nanoTime(); // Wait until measurement is finished while (this.echo.isHigh()) { // Wait until the echo pin is low, indicating the ultrasound was received back } long end = System.nanoTime(); // Output the distance float measuredSeconds = getSecondsDifference(start, end); int distance = getDistance(measuredSeconds); logger.info("Distance is: {}cm for {}s ", distance, measuredSeconds); var timeStamp = new SimpleDateFormat("HH.mm.ss").format(new Date()); this.data.getData().add(new XYChart.Data<>(timeStamp, distance)); }User interface. Thanks to TilesFX, a dashboard-style application can be created quickly. The complete construction of the interface is done in the class DashboardScreen.java. The following snippet shows a switch button to turn the LED on and off:
var ledSwitchTile = TileBuilder.create() .skinType(SkinType.SWITCH) .prefSize(200, 200) .title("LED") .roundedCorners(false) .build(); ledSwitchTile.setOnSwitchReleased(e -> gpioHelper.setLed(ledSwitchTile.isActive()));To show the distance measurement, I use a tile of the type SMOOTHED_CHART, which uses the XYChart.Series from DistanceSensorMeasurement, which is made available through GpioHelper.
var distanceChart = TileBuilder.create() .skinType(SkinType.SMOOTHED_CHART) .prefSize(500, 280) .title("Distance measurement") //.animated(true) .smoothing(false) .series(gpioHelper.getDistanceMeasurements()) .build();Application class. All elements are now ready to be combined into a JavaFX application class. Here’s how to initialize the GpioHelper and use it to initialize the DashboardScreen, and there’s some additional code to nicely close the application.
public class DashboardApp extends Application { private GpioHelper gpioHelper; @Override public void start(Stage stage) { Platform.setImplicitExit(true); this.gpioHelper = new GpioHelper(); var scene = new Scene(new DashboardScreen(this.gpioHelper), 640, 480); stage.setScene(scene); stage.setTitle("JavaFX demo application on Raspberry Pi"); stage.show(); // Make sure the application quits completely on close stage.setOnCloseRequest(t -> CleanExit.doExit(this.gpioHelper.getGpioController())); } public static void main(String[] args) { launch(); } } Running the application on the Raspberry Pi boardYou can start the application on your PC from an IDE and the UI will be shown, but not a lot will happen because Pi4J and the hardware components are needed. So let’s move to the Raspberry Pi! You first need to install Pi4J. This can be done with a single-line command:
$ curl -sSL https://pi4j.com/install | sudo bashThe final step is to get the compiled JAR file from your PC to the Pi board, which can be done with SSH, a USB stick, a download, or an SD card. Put the file in /home/pi and start it with java -jar:
$ cd /home/pi $ ls *.jar javamagazine-javafx-example-0.0.1-jar-with-dependencies.jar $ java -jar javamagazine-javafx-example-0.0.1-jar-with-dependencies.jar INFO be.webtechie.gpio.DistanceSensorMeasurement - Distance is: 103cm for 0.006021977s INFO be.webtechie.gpio.DistanceSensorMeasurement - Distance is: 265cm for 0.01544218s INFO be.webtechie.gpio.DistanceSensorMeasurement - Distance is: 198cm for 0.011520567s INFO be.webtechie.gpio.ButtonChangeEventListener - Button state changed to high INFO be.webtechie.gpio.ButtonChangeEventListener - Button state changed to lowSome logging information will be shown on the screen first, and a bit later the JavaFX screen is opened. The distance chart gets a new value every second, and the button chart is updated with every push or release of the button. The LED can be toggled with the switch button on the screen in one of the tiles. See Figure 11.

Figure 11. Photo of the running application with the Raspberry Pi and other hardware components
ConclusionOnce you know which Java version needs to be used on the Pi, you can get started very quickly with simple Java test files and extend them with a JavaFX user interface. Building a complex application requires some more work to set up everything in your IDE and to be able to do a test run, but doing so allows you to develop on a PC and run on a Pi very easily.
I am curious what you are going to build with Raspberry Pi. Please share your work on Twitter with the hashtag #JavaOnRaspberryPi. To learn more, please check out my book, Getting Started with Java on Raspberry Pi.
Acknowledgments: Many thanks to Gluon HQ for all the work on JavaFX and to BellSoft for Liberica JDK including JavaFX for the Raspberry Pi. Code for this example application has been reviewed by Pieterjan Deconinck, my most critical—in the best meaning of the word—colleague.
]]>Volcamp by Geek&Terroir est la première conférence au cœur des volcans d'Auvergne faite pour les passionnés de technologie, de développement et de terroir. Programmez! est partenaire de l'événement.
Le programme est en cours de construction. Les thèmes couverts seront :
Ceci sous plusieurs formats : Conférence, Retours d'expérience, Atelier, Eclairage.
Jeudi 15 et vendredi 16 octobre 2020
Hall32
32 Rue du Clos Four
63100 Clermont-Ferrand
Site : volcamp.io